|
|
| Riga 147: |
Riga 147: |
| | ** '''Cross join:''' Corrisponde al prodotto cartesiano. La sua forma è ''R CROSS JOIN S'' | | ** '''Cross join:''' Corrisponde al prodotto cartesiano. La sua forma è ''R CROSS JOIN S'' |
| | * '''Divisione:''' l’operazione di divisione ''R / S'' è l’insieme di tutti valori di ''x'' (in forma di tuple unarie) tali che per ogni valore ''y'' in ''S'' ci sia una tupla ''|x,y|'' in ''R''. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così: ''<math>\pi_x</math>((<math>\pi_x</math>(A) x B) – A)''. | | * '''Divisione:''' l’operazione di divisione ''R / S'' è l’insieme di tutti valori di ''x'' (in forma di tuple unarie) tali che per ogni valore ''y'' in ''S'' ci sia una tupla ''|x,y|'' in ''R''. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così: ''<math>\pi_x</math>((<math>\pi_x</math>(A) x B) – A)''. |
| − | ----
| |
| − | ----
| |
| − | ----
| |
| | | | |
| − | Lo standard dei linguaggi SQL usa la parola table per indicare relazione.
| + | ==Progettazione di una base di dati== |
| − | CREATE TABLE, usato per definire una nuova tabella (CREATE TABLE Studenti )
| + | ===Analisi dei requisiti=== |
| − | CREATE TABLE < nome relazione >
| + | Il primissimo passo nella progettazione è capire quali dati devono essere memorizzati, quali applicazioni devono essere costruite su di essi e quali operazioni sono più frequenti e soggette a requisiti prestazionali. |
| − | (< specifica colonna > [, < specifica colonna > ]);
| |
| − | < specifica colonna >, ha il seguente formato
| |
| − | < nome colonna > < dominio > [DEFAULT < valore default >]
| |
| − | dove < dominio > è il dominio della colonna, ed è uno dei tipi di dato SQL;
| |
| − | < valore default > è un valore del dominio, assunto dalle tuple se nessun valore è specificato per la colonna.
| |
| − | INSERT, usato per inserire le tuple
| |
| − | INSERT
| |
| − | INTO R [(C…C°)]
| |
| − | {VALUES (e…e°)| sq};
| |
| − | (e…e°) è una lista di valori da assegnare alla nuova tupla, questi sono assegnati in base ad una corrispondenza posizionale
| |
| − | sq, è una sub-query
| |
| − | le tuple generate come risposta alla sq vengono inserite nella relazione R
| |
| − | la clausola di proiezioni di sq deve contenere colonne compatibili con le colonne di R a cui si assegnano valori
| |
| − | il dominio della colonna C(i=1,…., n) deve essere compatibile con il dominio della colonna i-esima contenuta nella clausola di proiezione di SQL.
| |
| − | Tutte le colonne non esplicitamente elencate ricevono il valore nullo o il valore di default.
| |
| − | DELETE, usato per cancellare le tuple
| |
| − | DELETE
| |
| − | FROM R[alias]
| |
| − | [WHERE F];
| |
| − | il nome della relazione può essere associato ad un alias se è necessario riferire a tuple di tale relazione una qualche sotto-interrogazione presente in F
| |
| − | se non viene specificata alcuna clausola di qualificazione vengono cancellate tutte le tuple.
| |
| − | UPDATE, usato per modificare i valori in una riga esistente
| |
| − | UPDATE R[alias]
| |
| − | SET C={e |NULL},…, C°={e° | NULL}
| |
| − | [WHERE F];
| |
| − | il nome della relazione può avere associato un alias se è necessario riferire tuple di tale relazione in una qualche sotto-interrogazione presente in F
| |
| − | C={e |NULL},…, C°={i=1 | NULL}, è un’espressione di assegnamento che specifica che alla colonna C, deve essere assegnato il valore dell’espressione e.
| |
| − | Questa può essere una costante, spesso funzione dei valori correnti delle tuple da modificare, o una sub-query
| |
| − | si può specificare che alla colonna sia assegnato il valore nullo.
| |
| | | | |
| − | Per definire una chiave primaria in SQL viene usato il comando PRIMARY KEY, mentre per dichiarare un sottoinsieme delle colonne di una tabella si usa UNIQUE. | + | Per fare ciò vengono definite le caratteristiche della base di dati in maniera informale, mediante interviste con gli utenti, |
| − | La presenza di NULL in una chiave esterna non viola il vincolo di chiave. Il comando in SQL è FOREIGN KEY che ha delle opzioni aggiuntive, sul come comportarsi una volta implementata la chiave esterna.
| + | analisi di altre basi di dati esistenti, normative, ambiente operativo ecc. |
| − | FOREIGN KEY(< lista nomi colonne >)
| |
| − | REFERENCES < nome relazione >
| |
| − | [ON DELETE { NO ACTION |
| |
| − | CASCADE | SET NULL | SET DEFAULT )}
| |
| − | [ ON UPDATE { NO ACTION |
| |
| − | CASCADE | SET NULL | SET DEFAULT )}
| |
| − | l’opzione predefinita è NO ACTION(l’azione deve essere ignorata).
| |
| − | CASCADE dice che se una riga viene cancellata, tutte le sue righe che la referenziano devono essere eliminate. Lo stesso vale per il caso di un UPDATE, dove l’aggiornamento viene propagato a ciascuna riga,
| |
| − | ON DELETE permette di specificare le azioni da eseguire nel caso di cancellazione di una tupla riferita tramite chiave esterna,
| |
| − | ON UPDATE permette di specificare le azioni da eseguire nel caso di modifica del valore di chiave di una tupla riferita tramite chiave esterna
| |
| − | Per default un vincolo viene verificato al termine di ogni istruzione SQL che potrebbe portare ad una violazione, e se questa ci fosse il comando viene rifiutato.
| |
| − | L’SQL permette di specificare che un vincolo sia in modalità DEFERRED o IMMEDIATE: SET CONSTRAINT vincolo DEFERRED.
| |
| − | Un’interrogazione di una base di dati relazionale è una domanda sui dati, e la risposta consiste in una nuova relazione contenente il risultato. Un esempio di query è:
| |
| − | SELECT*
| |
| − | FROM
| |
| − | WHERE
| |
| − | *significa che vogliamo tutti i campi delle tuple che compongono il risultato.
| |
| − | Una vista è una tabella le cui righe non sono esplicitamente memorizzate nella base dati, ma sono calcolate quando necessario in base a una definizione di vista.
| |
| − | Questa può essere usata come in una tabella di base per definire nuove interrogazioni o viste.
| |
| − | DROP TABLE, per eliminare una tabella e la sua forma è:
| |
| − | DROP TABLE < nome relazione >
| |
| − | { RESTRICT | CASCADE };
| |
| − | se viene specificata l’opzione RESTRICT, la relazione viene cancellata solo se non è riferita da altri elementi dello schema della base di dati;
| |
| − | se viene specificata l’opzione CASCADE, la relazione e tutti gli elementi dello schema della base di dati che eventualmente la riferiscono vengono cancellati.
| |
| − | ALTER TABLE, modifica la struttura di una tabella esistente e la sua forma è:
| |
| − | ALTER TABLE < nome relazione > < modifica >;
| |
| − | < modifica > è la modifica da effettuare, tra l’aggiunta di una nuova colonna, modifica di una colonna e l’eliminazione.
| |
| | | | |
| − | SQL:I linguaggi di basi dati come SQL permettono all’utente di specificare per quali relazioni e quali attributi è necessario mantenere l’integrità referenziale( e le azioni da eseguire in caso di violazione). La forma base di un’interrogazione SQL è:
| + | L’output è un documento in linguaggio naturale di specifica dei requisiti, che si possono suddividere in alcune categorie principali: |
| − | SELECT [DISTINCT] lista-select
| + | * '''Requisiti informativi:''' caratteristiche e tipologie dei dati |
| − | FROM lista-from
| + | * '''Requisiti sulle operazioni:''' esplicitati nel carico di lavoro |
| − | WHERE qualificazione
| + | * '''Requisiti sui vincoli di integrità ed autorizzazione:''' proprietà da assicurare ai dati, in termini di correttezza e protezione |
| − | Lista-select, è una lista di nomi di colonne delle tabelle nominate nella lista-from. I nomi di colonne possono avere come prefisso una variabile di range.
| + | * '''Requisiti sulla popolosità della base di dati:''' volume dei dati |
| − | Lista-from, è una lista di nomi di tabelle. Un nome di tabella può essere seguito da una variabile di range(questa è utile quando lo stesso nome di tabella appare più volte nella lista-from).
| |
| − | Qualificazione, è una combinazione booleana di condizioni nella forma espressione op espressione, dove op è uno degli operatori di confronto.
| |
| − | Ogni interrogazione deve avere una clausola SELECT, che specifica le colonne da includere nel risultato, e una clausola FROM, che specifica un prodotto cartesiano di tabelle. La clausola opzionale WHERE specifica condizioni di selezione sulle tabelle menzionate nella clausola FROM.
| |
| − | Se omettiamo la parola chiave DISTINCT, otterremo una copia della riga (v,e), e la risposta sarebbe un multi-insieme di righe.
| |
| − | Il processo d’interrogazione di un DB consta in:
| |
| − | caricamento della lista di attributi;
| |
| − | scarto delle tuple che non soddisfano la qualificazione;
| |
| − | eliminazione degli attributi che non sono nella lista-from.
| |
| − | Un multi-insieme è un simile ad un insieme, nel senso che è una collezione non ordinata di elementi, ma possono esserci diverse copie, e il numero di copie è significativo: due multi-insiemi possono avere gli stessi elementi e tuttavia essere diversi, poiché il numero di copie dello stesso elemento è diverso.
| |
| − | Tipi numerici esatti:
| |
| − | INTEGER; la precisione di questo tipo di dato è espressa in numero di bit, a seconda della specifica implementazione di SQL,
| |
| − | SMALLINT; l’unico requisito è che la precisione di questo tipo di dato sia non maggiore della precisione del tipo di dato INTEGER. Questo viene usato per eventuali ottimizzazioni in quanto i valori richiedono minore spazio di memorizzazione,
| |
| − | BIGINT; l’unico requisito è che la precisione di questo tipo di dato sia non minore della precisione del tipo di dato INTEGER,
| |
| − | NUMERIC; caratterizzato da una precisione(numero totale di cifre) e una scala(numero di cifre dopo la virgola), il valore default per la precisione è 1 e per la scala è 0,
| |
| − | DECIMAL; simile a NUMERIC, ma la specifica di questo tipo di dato ha la forma: DECIMAL[(precisione[,scala])].
| |
| − | Tipi numerici approssimati:
| |
| − | REAL; rappresenta valori reali a singola precisione in virgola mobile, e la precisione dipende dalla specifica implementazione si SQL,
| |
| − | DOUBLE PRECISION; rappresenta valori reali a doppia precisione in virgola mobile, e questa dipende sempre dall’implementazione di SQL(però deve essere maggiore della precisione di tipo REAL),
| |
| − | FLOAT; rappresenta valori reali alla precisione desiderata, ed ha la forma FLOAT[(precisione)]. La precisione minima specificabile è 1.
| |
| − | Tipi di dato carattere:
| |
| − | CHARACTER; rappresenta stringhe di caratteri di lunghezza predefinita, spesso abbreviato in CHAR. La specifica ha il formato CHAR[(n)], con n lunghezza delle stringhe. E’ possibile usare come valore una stringa di lunghezza inferiore a n, che viene completata con spazi fino a raggiungere tale lunghezza,
| |
| − | CHARACTER VARYING; rappresenta stringhe di caratteri di lunghezza massima predefinita. Spesso abbreviato in VARCHART, e la sua forma è VARCHART(n), dove n è la lunghezza massima delle stringhe.
| |
| − | Tipi di dato temporali:
| |
| − | DATE; rappresenta le date espresse come anno(4cifre), mese(2cifre) e giorno(2cifre),
| |
| − | TIME; rappresenta i tempi espressi come ora(2cifre), minuto(2cifre) e secondo(2cifre),
| |
| − | TIMESTAMP; rappresenta una “concatenazione” fra DATE e TIME. Permette di rappresentare timestamp che consistono in: anno, mese, giorno, ora, minuto, secondo e microsecondo,
| |
| − | INTERVAL; rappresenta una durata temporale in riferimento ad uno o più qualificatori. I valori di questo tipo son rappresentati dalla parola chiave INTERVAL seguita da una stringa che esprime la durata in termini di uno o più qualificatori. Se sono presenti due qualificatori, il primo è più ampio del secondo e sono separati dalla parola chiave TO.
| |
| − | Tipo di dato:
| |
| − | BOOLEAN; i valori di tali tipo sono TRUE, FALSE, UNKNOWN(questo viene introdotto per la gestione dei confronti con valori nulli,
| |
| − | CHARACTER LARGE OBJECT(CLOB); permette di rappresentare sequenze di caratteri di elevate dimensioni,
| |
| − | BINARY LARGE OBJECT(BLOB); permette di rappresentare sequenze di bit di elevate dimensioni.
| |
| − | E’ possibile convertire un valore ad un altro tipo mediante l’operatore di CAST
| |
| − | CAST (e) AS < tipo target >
| |
| − | AS: per introdurre una variabile di range.
| |
| − | I nomi delle tabelle possono essere implicitamente usati come variabili in linea. Si ha la necessità di introdurre esplicitamente le variabili di range solo quando la clausola FROM contiene più di una occorrenza di una relazione. Se una variabile di range è stata introdotta nella relazione, un nome di tabella non può essere usato come variabile di range esplicita.
| |
| − | Ogni elemento in una lista-select può essere della forma espressione AS nome_colonna ( questo è il nuovo nome che la colonna avrà nel risultato dell’interrogazione. Inoltre, ogni termine in una qualificazione può anche essere rappresentato nella forma generale espressione1 = espressione2.
| |
| − | L’SQL permette il pattern matching, su valori di tipo stringa, attraverso l’uso dell’operatore LIKE, insieme all’uso dei caratteri jolly %( zero o più caratteri qualunque) e ( esattamente un carattere qualunque). Quindi “AB%” denota una qualunque stringa che contiene almeno tre caratteri, con il secondo ed il terzo uguali a A e B.
| |
| − | SQL fornisce tre comandi per la manipolazione degli insiemi che estendono la forma d’interrogazione basilare, e sono:
| |
| − | UNION, restituisce tutte le tuple distinte restituite da almeno una delle sotto-interrogazioni a cui è applicato. Se si usa la clausola ORDER BY, questa deve essere usata una sola volta alla fine dell’interrogazione e non alla fine di ogni SELECT,
| |
| − | INTERSECT, corrisponde all’intersezione, restituisce le tuple restituite da entrambe le sotto interrogazioni a cui è applicato.
| |
| − | EXCEPT, corrisponde alla differenza, e restituisce le tuple della seconda sotto-interrogazione a cui è applicato.
| |
| − | Questo linguaggio fornisce anche altre operazioni sugli insiemi:
| |
| − | IN, per controllare se un elemento è in un dato insieme. C IN(v,….v°), nella forma negata C NOT IN(v,….v°).
| |
| − | ANY
| |
| − | ALL, per confrontare un valore con gli elementi di un dato insieme, usando l’operatore di confronto op
| |
| − | EXISTS, per controllare se un insieme è vuoto.
| |
| − | BETWEEN, permette di determinare le tuple che contengono in un dato attributo valori in un intervallo dato. C BETWEEN v AND v° , nella forma negata invece C NOT BETWEEN v AND v°,
| |
| − | ABS(N); calcola il valore assoluto del valore numerico N,
| |
| − | MOD(n,b); calcola il resto intero della divisione n per b.
| |
| − | UNION, INTERSECT ed EXCEPT possono essere usati su qualsiasi coppia di tabelle che siano compatibili rispetto all’unione, cioè che abbiamo lo stesso numero e tipo di colonne.
| |
| − | Nel caso si UNION i duplicati vengono eliminati automaticamente. Per mantenerli è necessario aggiungere ALL (UNION ALL). Lo stesso discorso vale per INTERSECT ed EXCEPT.
| |
| − | Espressioni e funzioni: un’espressione usata nella clausola di proiezione di un’interrogazione, dà luogo ad una colonna, detta virtuale, non presente nella relazione su cui si effettua l’interrogazione.
| |
| − | Le colonne virtuali non sono fisicamente memorizzate, ma sono calcolate dinamicamente come risultato dell’esecuzione dell’interrogazione.
| |
| − | Espressioni e funzioni per stringhe:
| |
| − | Operatore di concatenazione denotato da ||,
| |
| − | LENGHT(str), restituisce la lunghezza della stringa str, in numero di caratteri,
| |
| − | UPPER(str) e LOWER(str), trasformano la stringa str in caratteri tutti maiuscoli o tutti minuscoli, rispettivamente,
| |
| − | SUBSTR(str, m,[n]), estrae dalla stringa str la sottostringa dal carattere di posizione m per una lunghezza n,
| |
| − | TRIM[str°] FROM str, elimina dalla stringa str° i caratteri in str.
| |
| − | Un’interrogazione annidata è un’interrogazione che al suo interno ha un’altra interrogazione. Questa solitamente appare nella clausola WHERE, o anche in FROM o HAVING. Se una sub-query scalare restituisce più di una tupla si genera un errore di run-time, e se nessuna tupla verifica la sotto-interrogazione, viene restituito il valore NULL.
| |
| − | E’ anche possibile selezionare più di una colonna tramite sotto-interrogazioni, in tal caso è necessario apporre delle parentesi alla lista delle colonne a sinistra dell’operatore di confronto. Ad esempio, voglio elencare gli impiegati con la stessa mansione di Martini;
| |
| − | SELECT Nome FROM Impiegati
| |
| − | WHERE(Mansione, Stipendio) = (SELECT
| |
| − | Mansione, Stipendio FROM Impiegati
| |
| − | WHERE Nome = “Martini”);
| |
| − | Una sub-query può contenere a sua volta un’altra sub-query. E’ possibile definire sotto-interrogazioni che sono eseguite ripetutamente per ogni tupla candidata considerata nella valutazione dell’interrogazione esterna, e ogni volta che questa considera una tupla candidata, deve invocare la sotto-interrogazione. Questo tipo viene chiamato correlato, dato che ogni esecuzione è correlata al valore di uno o più attributi delle tuple candidate nell’interrogazione principale. Per poter fare riferimento alle colonne delle tuple candidate nell’interrogazione esterna si fa uso degli alias di relazione(questo è definito nell’interrogazione esterna e riferito nella sotto-interrogazione correlata. Sono utili quando si vuole fare riferimento a due diverse tuple della stessa relazione.).
| |
| − | UNIQUE, quando applichiamo questo comando ad una sotto-interrogazione, la condizione che ne risulta ritorna vero se nessuna riga appare due volte nella risposta all’interrogazione, se non ci sono duplicati. Ritorna vero se la risposta è vuota.
| |
| − | Operatori di aggregazione:
| |
| − | COUNT ([DISTINCT] A) , è numero di valori unici della colonna A,
| |
| − | SUM ([DISTINCT] A) , la somma di tutti i valori unici nella colonna A,
| |
| − | AVG ([DISTINCT] A) , la media di tutti i valori unici nella colonna A,
| |
| − | MAX (A) , il valore massimo della colonna A,
| |
| − | MIN (A) , il valore minimo della colonna A.
| |
| − | Non ha senso specificare DISTINCT insieme a MIN e MAX.
| |
| − | Le clausole GROUP BY e HAVING;
| |
| − | SELECT [DISTINCT] lista-select
| |
| − | FROM lista-from
| |
| − | WHERE qualificazione
| |
| − | GROUP BY lista gruppo
| |
| − | HAVING qualificazione gruppo.
| |
| − | La lista-select consiste di una lista di nomi di colonne e una lista di termini della forma aggop(nome-colonna) AS nuovo-nome. Ogni colonna che appare nella lista dei nomi deve apparire nella lista-gruppo.
| |
| − | Le espressioni che compaiono nella qualificazione gruppo della clausola HAVING devono avere un singolo valore per gruppo. L’idea di base è che la clausola HAVING ( può essere una combinazione Booleana di predicati, i quali tuttavia possono solo coinvolger funzioni di gruppo) determina se per ogni gruppo dato debba essere generata una riga della risposta.
| |
| − | Un’importante restrizione ci dice che una clausola di protezione di una query contenente GROUP BY può includere solamente:
| |
| − | una o più colonne tra le colonne che compaiono nella suddetta clausola,
| |
| − | funzioni di gruppo(che possono apparire in funzioni aritmetiche).
| |
| − | Le funzioni di gruppo permettono di estrarre informazioni da gruppi di tuple invece di una relazione, queste si basano su due concetti:
| |
| − | il partizionamento delle tuple di un relazione in base al valore di uno o più colonne della relazione,
| |
| − | il calcolo della funzione di gruppo per ogni gruppo ottenuto col partizionamento.
| |
| − | Una funzione di gruppo ha come argomento una colonna e si applica all’insieme dei valori di questa colonna, estratti dalle tuple che appartengono allo stesso gruppo.
| |
| − | E’ possibile applicare queste funzioni senza partizionamento e in tal caso saranno applicate ad un unico gruppo contente tutte le tuple della relazione.
| |
| − | Se GROUP BY viene omesso l’intera tabella viene vista come un singolo gruppo
| |
| − | COUNT, se questo non include DISTINCT, allora COUNT(*) dà la stessa risposta di COUNT(x), dove x è un qualunque insieme di attributi.
| |
| − | L’SQL fornisce un valore di colonna speciale chiamato null da usare quando il valore della colonna è sconosciuto oppure inapplicabile.
| |
| − | Possiamo impedire l’uso dei valori null specificando NOT NULL come parte della definizione dei campi. Inoltre i campi in una chiave primaria non posso assumere valori null, quindi vi è un vincolo di NOT NULL, implicito per ogni campo elencato in un vincolo di PRIMARY KEY.
| |
| − | Si può specificare vincoli sulla tabella usando vincoli di tabella, che hanno la forma CHECK espressione-condizionale.
| |
| − | In un comando CREATE TABLE, la clausola CHECK può comparire;
| |
| − | di seguito alla definizione di una colonna ( vincoli di CHECK su colonna )
| |
| − | come clausola separata dall’interno della definizione della relazione ( vincoli CHECK su relazione ).
| |
| − | Specificando un vincolo CHECK vogliamo che ogni tupla nella relazione soddisfi la condizione. E’ consigliabile esprimere tramite CHECK solo le condizioni che devono essere verificate da ogni singola tupla della relazione cui associamo il vincolo.
| |
| − | E’ possibile assegnare nome ai vincoli associati alle definizioni di relazione facendo seguire la specifica del vincolo nella parola chiave CONSTRAINT e dal nome. Difetti specificare un nome per tutti i vincoli è utile per potersi poi riferire ad essi.
| |
| − | Le asserzioni servono per esprimere vincoli di integrità che coinvolgono più tuple o relazioni, e vengono così formulate:
| |
| − | CREATE ASSERTION < nome asserzione >
| |
| − | CHECK(< condizione >).
| |
| − | I vincoli di una tabella sono associati ad una tabella singola. Il soddisfacimento di questi vincoli è richiesto solo se la tabella associata è vuota, quando un vincolo coinvolge due o più tabelle, il meccanismo di vincoli sulle tabelle è in qualche modo anomalo, e non ciò che si desidera.
| |
| − | Un trigger è una procedura che viene eseguita dal DBMS in risposta a specifici cambiamenti nella base di dati ed è definita dal DBA. Questi son divisi in tre parti:
| |
| − | evento: un cambiamento nella base di dati che attiva il trigger;
| |
| − | condizione: un’interrogazione o un test che viene eseguito quando il trigger è attivato;
| |
| − | azione; procedura che viene eseguita quando il trigger è attivato e la sua condizione è verificata.
| |
| − | Una condizione di trigger può essere un comando vero/falso oppure un’interrogazione. Questa viene interpretata come vero se l’insieme di risposta non è vuoto, falso se l’opposto. L’azione di un trigger può esaminare la risposta all’interrogazione nella parte condizionale dei trigger , fare riferimento a valori vecchi e nuovi delle tuple modificate dal comando che ha attivato il trigger, eseguire nuove interrogazioni e apportare cambiamenti alla base di dati.
| |
| | | | |
| − | ==Progettazione di una base dati== | + | ===Progettazione concettuale=== |
| − | 1)Analisi dei requisiti: il primissimo passo nella progettazione è capire quali dati devono essere memorizzati, quali applicazioni devono essere costruite su di essi e quali operazioni sono più frequenti e soggette a requisiti prestazionali.
| |
| − | 2)Progettazione concettuale della base di dati: le informazioni raccolte nel passo di analisi dei requisiti vengono usate per elaborare una descrizione ad alto livello dei dati da memorizzare. Questo passo è sviluppato usando il modello entità-relazione, il quale fa parte di una famiglia di diversi modelli di dati ad alto livello, o semantici, usati nella progettazione delle basi di dati. Lo scopo è creare una semplice descrizione dei dati che approssimi il modo in cui utenti e sviluppatori pensano ad essi.
| |
| − | 3)Progettazione logica della base dati: dobbiamo scegliere un DBMS per implementare in nostro progetto, e convertire la progettazione concettuale in uno schema nel modello del DBMS scelto. La traduzione non è sempre univoca.
| |
| − | 4)Raffinamento dello schema: analizzare l’insieme di relazioni del nostro schema relazionale per identificare potenziali problemi, e a rifinirlo.
| |
| − | 5)Progettazione fisica della base di dati: consideriamo i carichi di lavoro attesi che la nostra base di dati dovrò sopportare, e raffiniamo il progetto per garantire che esso soddisfi i criteri di prestazioni richieste. Questo può consistere nella costruzione di indici su qualche tabella e nel raggruppamento di alcune tabelle, oppure può coinvolgere una riprogettazione sostanziale di intere parti dello schema ottenuto precedentemente.
| |
| − | 6)Progettazione delle applicazioni e della sicurezza.
| |
| − | Una entità è un oggetto nel mondo reale che si distingue da altri progetti. Vi sono anche insiemi di entità, e questi non hanno bisogno di essere disgiunti. Un entità è anche un’astrazione della realtà la cui informazione è indipendente dal dominio in cui l’entità è utilizzata. Invece un’istanza di entità sono specifici oggetti appartenenti ad una certa entità.
| |
| − | Un’entità è descritta usando un insieme di attributi. Tutte le entità di un dato insieme hanno gli stessi attributi: questo è ciò che s’intende con simili. La coppia (nome_di_attributo, dominio) viene chiamata attributo e ogni entità è caratterizzata da uno o più attributi(i quali possono essere monovalore, multivalore e compositi).
| |
| − | Per ogni attributo associato ad un insieme di entità, dobbiamo definire un dominio di valori possibili. Vi son diversi tipi di domini:
| |
| − | semplice, sono domini standard(interi, reali, booleani…), con intervalli ed insiemi di valori definiti per enumerazione dall’utente,
| |
| − | composti, l’insieme dei valori è dato dal prodotto cartesiano degli insiemi di valori associati ai domini componenti. Servono per associare un dominio agli attributi composti.
| |
| − | Le informazioni sui domini i un attributo non sono direttamente rappresentabili in un diagramma ER, sono però fondamentali per una corretta progettazione logica.
| |
| − | Inoltre per ciascun insieme di entità useremo una chiave. Questa è un insieme minimale di attributi i cui valori identificano univocamente una entità dell’insieme. Potrebbe esserci più di una chiave candidata, e in questo caso ne designiamo una come chiave primaria. Una chiave non può avere valori nulli, in alcuni casi la chiave può essere soltanto una dove il sistema non permette di averne di più.
| |
| − | | |
| − | | |
| − | | |
| − | | |
| − | | |
| − | | |
| − | | |
| − | | |
| − | | |
| − | Gli attributi vengono rappresentati con degli ovali, e se sono sottolineati sono delle chiavi primarie mentre le entità sono dei rettangoli.
| |
| − | Una relazione è un’associazione tra due o più entità.
| |
| − | Come per le entità potremmo voler raccogliere un gruppo di relazioni simili in un insieme di relazioni. Questo può essere visto come un insieme di n-tuple:
| |
| − | {( e1,… en) E1,…,en En}
| |
| − | Ciascuna n-tupla denota una relazione che coinvolge n entità, da e1 a en, dove l’entità ei appartiene all’insieme di entità Ei.
| |
| − | Una relazione può anche avere attributi descrittivi, i quali son usati per registrare informazioni sulla relazione, piuttosto che su ciascuna delle entità partecipanti.
| |
| − | Un’istanza di un insieme di relazioni è un insieme di relazioni, questa può esser vista come una “fotografia” dell’insieme di relazioni di un certo istante.
| |
| − | Gli insiemi di entità che partecipano ad una relazione non devono necessariamente essere distinti: qualche volta una relazione può coinvolgere entità dello stesso insieme.
| |
| − | Ruolo, è la funzione che un’istanza di entità esercita nell’ambito di un’associazione, e nel caso di un’associazione unaria il ruolo è sempre necessario.
| |
| − | Il modello ER offre costrutti per definire:
| |
| − | vincoli di cardinalità, sia per associazioni che per attributi. Questi si dividono in cardinalità minima( numero minimo d’istanze di un’associazione a cui le istanze delle entità coinvolte nell’associazione possono partecipare) e cardinalità massima( numero massimo di un’associazione a cui le istanze dell’entità coinvolte nell’associazione posso partecipare).
| |
| − | Data un’entità E ed un’associazione A:
| |
| − | i.c_max=1, ogni istanza di E può partecipare a non più di un’istanza di A,
| |
| − | ii.c_max=c_min=1, ogni istanza i E partecipa ad una ed una sola istanza di A,
| |
| − | iii.c_min=0, c_max=n, ogni istanza di E può partecipare ad un numero qualsiasi di istanze di A, anche nessuna.
| |
| − | vincoli d’identificazione, per entità. Identificatori per un’entità: insieme di attributi e/o entità che identificano le istanze dell’entità. Un identificatore è minimale se qualsiasi sottoinsieme proprio non è un identificatore. Le entità deboli ha sempre cardinalità(1,1) rispetto all’associazione attraverso cui avviene l’dentificazione.
| |
| − | Uno a uno: se c_max di E e di E°, rispetto ad A è 1;
| |
| − | Uno a molti: se c_max di E rispetto ad A è n e c_max di E° rispetto ad A è 1, o viceversa. Un impiegato può essere associato a molti altri reparti.
| |
| − | Molti a molti: l’insieme di relazioni Lavora_in, in cui un impiegato può lavorare in diversi reparti e ogni reparto può avere diversi impiegati.
| |
| − | Insieme di entità deboli: se c_max di E e di E°, rispetto ad A è n. Questa viene identificata univocamente solo considerando alcuni attributi in congiunzione con la chiave primaria di un’altra entità, che è chiamata proprietario identificante. Devono valere queste condizioni:
| |
| − | l’insieme di entità proprietarie e l’insieme di entità deboli devono partecipare in un insieme di relazioni uno-a-molti. Questo insieme di relazioni è chiamato insieme di relazioni identificanti dell’insieme di relazioni deboli
| |
| − | l’insieme di entità deboli deve aver partecipazione totale nell’insieme di relazioni identificanti.
| |
| − | Per identificare che si ha un’entità debole si usa un tratto più spesso.
| |
| − | Mentre per indicare che si ha una chiave parziale si userà una sottolineatura a tratti.
| |
| − | La specializzazione è il processo con cui s’individuano sottoinsiemi di un insieme di entità(la superclasse) che condividono alcune caratteristiche distintive. Tipicamente, la superclasse viene definita per prima,poi le sottoclassi, ed infine si aggiungono gli attributi specifici e gli insiemi di relazioni.
| |
| − | La generalizzazione consiste nell’identificare alcune caratteristiche comuni a una collezione di insiemi di entità e creare un nuovo insieme di entità che contiene quelle entità che possiedono caratteristiche comuni. Le sottoclassi si definiscono per prime, poi le superclassi, e poi si aggiungono tutti gli insiemi di relazioni che coinvolgono la superclasse.
| |
| − | I vincoli di disgiunzione determinano se a due sottoclassi è premesso contenere la stessa identità.
| |
| − | I vincoli di copertura determinano se le entità di una sottoclasse includono, nel loro complesso tutte le entità della superclasse.
| |
| − | L’aggregazione ci permette di indicare che un insieme di relazioni partecipa in un altro insieme di relazioni. Ciò viene illustrato con un riquadro tratteggiato intorno all’insieme di relazioni.
| |
| − | L’uso di un modello di dati semantico di alto livello offre nella progettazione concettuale il vantaggio addizionale che il progetto ad alto livello può essere rappresentato con diagrammi e facilmente compreso dalle molte persone che devono fornire informazioni utili al processo progettuale.
| |
| − | L’approccio normale consta nel considerare le necessità dei vari gruppo di utenti, risolvere i conflitti e generare un singolo insieme di requisiti. Un altro tipo di approccio consiste nello sviluppare schemi concettuali separati per i diversi gruppi di utenza, per poi integrarli. Per fare ciò si deve stabilire le corrispondenze tra le entità, le relazioni e gli attributi, e risolvere diversi tipi di conflitti.
| |
| − | | |
| − | Un insieme di entità è tradotto in una relazione in maniera molto semplice: ogni attributo di un insieme di entità diventa un attributo della tabella.
| |
| − | Per rappresentare una relazione, dobbiamo potere identificare ciascuna entità partecipante, e dare valori agli attributi descrittivi della relazione, quindi:
| |
| − | gli attributi della chiave primaria di ciascun insieme di entità partecipante, come campi di chiavi esterne
| |
| − | gli attributi descrittivi dell’insieme di relazioni.
| |
| − | Se un insieme di relazioni coinvolge n insiemi di entità, e m di essi sono collegati con frecce ne diagramma ER, la chiave per ciascuno di questi m insiemi costituisce una chiave per la relazione in cui l’insieme è tradotto. Quindi abbiamo m chiavi candidate, e una di queste dovrebbe essere scelta come chiave primaria.
| |
| − | Un secondo approccio per tradurre un insieme di relazioni con vincoli di chiave si rivela spesso migliore, perché evita di creare una tabella distinta per l’insieme di relazioni.
| |
| − | L’idea è di includere le informazioni sull’insieme di relazioni nella tabella corrispondente all’insieme di entità con la chiave, sfruttando il vincolo di chiave.
| |
| − | Lo svantaggio in questo è che potrebbe esserci uno spreco di spazio. In tal caso i campi aggiunti dovrebbero essere riempiti con valori null. La prima traduzione evita questa inefficienza, ma alcune interrogazioni importanti richiedono di combinare informazioni da due relazioni, il che può essere un operazione lenta.
| |
| − | Un insieme di entità deboli partecipa sempre in una relazione binaria uno-a-molti e ha vincoli di chiave e di partecipazione totale. Questa ha solo una chiave parziale, e quando un’entità proprietaria viene cancellata, vogliamo che vengano eliminate anche le entità deboli collegate.
| |
| − | | |
| − | ==PROGETTAZIONE CONCETTUALE==
| |
| − | | |
| − | La progettazione concettuale di una base di dati ci fornisce un insieme di schemi di relazione e VI che possono essere considerati un buon punto di partenza per il progetto finale. Permette di rappresentare i dati in modo indipendente da ogni sistema, cercando di descrivere i concetti del mondo reale.
| |
| − | Presentiamo ora una panoramica sui problemi che il raffinamento degli schemi intendo risolvere:
| |
| − | problemi causati dalla ridondanza: memorizzare la stessa informazione in maniera ridondante, cioè in diversi posti all’interno della stessa base di dati può portare a diversi problemi:
| |
| − | memorizzazione ridondante;
| |
| − | anomalie da aggiornamento, se una coppia di questi dati ripetuti viene aggiornata si crea un’inconsistenza, a meno di aggiornare anche tutte le altre copie;
| |
| − | anomalie da inserimento, potrebbe non essere possibile registrare certe informazioni, a meno di inserire anche qualche altra informazione non correlata;
| |
| − | anomalie di cancellazione.
| |
| − | Idealmente vorremmo degli schemi che non permettano ridondanza, ma quanto meno vogliamo poter identificare gli schemi che lo permettono:
| |
| − | valori null: questi non possono fornire una soluzione completa, ma possono aiutare. Questi valori possono essere utili per le anomalie da inserimento e cancellazione.
| |
| − | decomposizione, la ridondanza nasce quando uno schema relazionale forza una associazione tra attributi che non è naturale. Le dipendenze funzionali possono essere usate per identificare tali situazioni e per suggerire raffinamenti dello schema. Molti problemi che nascono dalla ridondanza possono essere risolti sostituendo una relazione con una collezione di relazioni “più piccolo”. Una decomposizione di uno schema di relazione r consiste nella sostituzione della schema di relazione con due(o più) schemi di relazione ciascuno dei quali contiene un sottoinsieme di attributi di R, e la cui unione include tutti tali attributi. Noi vogliamo memorizzare le informazioni in ogni data istanza di r memorizzandone le proiezioni. Se non si sta attenti con la decomposizione si possono creare più problemi di quanti se ne vogliano.
| |
| − | la proprietà senza perdita(lossless join) ci permette di recuperare qualunque istanza di una relazione decomposta a partire dalle corrispondenti istanze delle relazioni componenti tramite operazioni di join;
| |
| − | la proprietà di conservazione delle dipendenze ci consente di mantenere qualunque vincolo della relazione originaria semplicemente imponendo alcuni vincoli su ciascuna delle relazioni componenti. Ossia non abbiamo bisogno di effettuare join delle relazioni più piccolo per controllare se viene violato un vincolo della relazione originale.
| |
| − | La decomposizione potrebbe migliorare le prestazioni, nel caso in cui la maggior parte delle interrogazioni degli aggiornamenti esaminano solo una delle relazioni componenti, che è più piccola della relazione originale.
| |
| − | Dipendenze funzionali: DF è un tipo di VI che generalizza il concetto di chiave. Sia R uno schema di relazione e siano X e Y insiemi non vuoti di attributi di R, diciamo che un’istanza r di R soddisfa la DF X Y (si legge X determina funzionalmente Y, o X determina Y) se per ogni coppia di tuple t1 e t2 in r vale al seguente:
| |
| − | se t1.X = t2.X , allora t1.Y = t2.Y
| |
| − | Una DF X Y essenzialmente dice che se due tuple coincidono sui valori dell’attributo X, devono anche avere lo stesso valore per l’attributo Y.
| |
| − | Un’istanza legale di una relazione soddisfare tutti i VI specificati. Quindi guardando l’istanza di una relazione, potremmo essere in grado di dire che una certa DF non è valida, però non possiamo mai dedurre che una DF è valida solo guardando una o più istanza di una relazione, perché una DF, diversamente da un VI, è un’affermazione su tutte le possibili istanze legali di una relazione.
| |
| − | La definizione di una DF non richiede che l’insieme X sia minimale: l’ulteriore condizione di minimalità deve essere soddisfatta perché X sia una chiave. Se vale X Y, dove Y è l’insieme di tutti gli attributi, ed esiste qualche sottoinsieme X di tale che V Y, allora X è una superchiave.
| |
| − | Diciamo che una DF f è implicata da un dato insieme F di DF se f vale su ogni istanza di relazione che soddisfa tutte le dipendenze in F, f vale ogni volta che tutte le DF valgono in F.
| |
| − | Chiusura di un insieme di DF, l’insieme di tutte le DF implicate in un dato insieme F di DF è detto chiusura di F, denotato come F+. Come possiamo inferire(calcolare la chiusura di un dato insieme)?
| |
| − | Con gli Assiomi si Armstrong, i quali possono essere applicati per inferire tute le DF implicate da un insieme F di DF.
| |
| − | riflessività, se X Y, allora X Y;
| |
| − | aumento, se X Y allora XZ YZ per ogni Z;
| |
| − | transitività, se X Y e Y X, allora X Z.
| |
| − | Teorema 1 gli assiomi di Armstrong sono corretti, nel senso che generano solo DF in F+ quando sono applicati a un insieme F di DF. Sono anche completi, nel senso che ripetute applicazioni di queste regole generano tutte le DF nella chiusura F+.
| |
| − | Quando si parla di F+ conviene usare alcune regole addizionali:
| |
| − | unione: se X Y e X Z, allora X YZ;
| |
| − | decomposizione: se X YZ, allora X Y e X Z.
| |
| − | in una DF banale, la parte destra contiene solo attributi che appaiono anche nella parte sinistra; tali dipendenze valgono sempre per via della riflessività. Usando questa possiamo generare tutte le dipendenze banali, che hanno la forma:
| |
| − | X Y, dove Y X, X ABC e Y ABC.
| |
| − | Dalla transitività otteniamo A C.
| |
| − | Dall’aumento otteniamo le dipendenze non banali:
| |
| − | AC BC, AB AC, AB CB.
| |
| − | Chiusura degli attributi, se volgiamo controllare se una data dipendenza, diciamo X Y, è nella chiusura di un insieme F di DF, possiamo farlo in maniera efficiente senza calcolare la chiusura stessa.
| |
| − | Prima troviamo la chiusura degli attributi X+ rispetto a F, che è l’insieme degli attributi A tali che X A può essere derivata usando gli Assiomi di Armstrong. Questo è l’algoritmo di calcolo:
| |
| − | chiusura = X;
| |
| − | ripeti fin quando non ci sono più cambiamenti: {
| |
| − | se c’è una DF U V in F tale che U chiusura,
| |
| − | allora chiusura = chiusura V
| |
| − | }
| |
| − | Teorema 2 l’algoritmo mostrato calcola la chiusura dell’insieme X di attributi rispetto all’insieme F delle DF.
| |
| − | Forme normali, dato uno schema di relazione, abbiamo bisogno di decidere se esso sia un buon progetto o se c’è necessità di decomporlo in relazioni più piccole. Una tale decisione deve essere guidata dalla comprensione di quali problemi sono presenti nello schema corrente.
| |
| − | Le forme normali basate su DF sono la prima forma normale (1NF), la seconda(2NF), la terza(3NF) e la forma normale di Boyce-Codd(BCNF).
| |
| − | Una relazione è nella 1NF se ogni campo contiene solo valori atomici, cioè niente liste o insiemi. La 2NF ha un interesse storico. La 3NF e la BCNF sono importanti dal punto di vista della progettazione di una base di dati.
| |
| − | forma normale di Boyce-Codd, sia R uno schema di relazione, F sia l’insieme delle DF date su R, X sia un sottoinsieme degli attributi di R, e A un attributo di R. R è nella BCNF se per ogni DF X A in F vale una delle seguenti asserzioni:
| |
| − | A X, cioè è una DF banale,
| |
| − | X è una superchiave.
| |
| − | In una relazione in BCNF le sole dipendenze non banali sono quelle in cui una chiave determina alcuni attributi. Perciò ogni tupla può essere vista come un’entità o relazione, identificata da una chiave e descritta dai restanti attributi.
| |
| − | La BCNF assicura che nessuna ridondanza può essere rilevata usando solo le informazioni delle DF. Quindi è la più desiderabile delle forme normali, se prendiamo in considerazione solo le informazioni delle DF.
| |
| − | Se X è una chiave, allora y1=y2, il che significa ce le due tuple sono identiche. Poiché una relazione è definita come un insieme di tuple, non possiamo avere due copie della stessa tupla.
| |
| − | Se una relazione è in BCNF, ogni campo di ciascuna tupla registra una parte d’informazione che non può essere dedotta dall’istanza della relazione.
| |
| − | terza forma normale, sia R uno schema di relazione, F l’insieme delle DF date su R, X un sottoinsieme degli attributi di R, e A un attributo di R. R è in 3NF se per ogni DF X A in F vale:
| |
| − | A X, cioè è una DF banale
| |
| − | X è una superchiave
| |
| − | A fa parte di una chiave di R.
| |
| − | Supponiamo che una dipendenza X A provochi una violazione della 3NF, sono possibili due casi:
| |
| − | 1)X è un sottoinsieme proprio di qualche chiave K. Questa viene chiamata dipendenza parziale e viene memorizzato la coppia (X,A) in maniera ridondante.
| |
| − | 2)X non è un sottoinsieme proprio di una chiave. Una tale dipendenza è a volte chiamata dipendenza transitiva, perché significa che abbiamo una catena di dipendenze K X A. Il problema è che non possiamo associare un valore X con un valore K a meno di associare anche un valore A con un valore X.
| |
| − | Nella 3NF è possibile qualche ridondanza. I problemi associati alle dipendenze parziali e transitive persistono se c’è una dipendenza non banale X A e X non è una superchiave, anche se la relazione è nella forma 3NF perché A è parte di una chiave.
| |
| − | Proprietà delle decomposizioni;
| |
| − | - decomposizioni senza perdita, sia R uno schema di relazione e sia F un insieme di DF su R: una decomposizione di R in due schemi con insiemi di attributi X e Y si dice decomposizione senza perdita rispetto a F se per ogni istanza r di R che soddisfa le dipendenze in F, x(r) >< y ( r ) = r. Possiamo tornare alla relazione originale a partire dalle relazioni della decomposizione.
| |
| − | Tutte le decomposizioni usate per eliminare la ridondanza devono essere senza perdita d’informazione.
| |
| − | Teorema 3 sia R una relazione e F un insieme di DF che valgono su R. la decomposizione di R in due relazioni con insiemi di attributi R1 e R2 è senza perdita d’informazione se e solo se F+ contiene la DF R1R2 R1 oppure la DF R1R2 R2.
| |
| − | - decomposizione con conservazione delle dipendenze, permette di applicare tutte le DF esaminando una singola istanza di relazione su ciascun inserimento o modifica di una tupla.
| |
| − | | |
| − | ==SQL==
| |
| − | | |
| − | L’uso di comandi SQL in un programma scritto in un linguaggio ospite è chiamato SQL incapsulato, o embedded SQL.
| |
| − | I comandi SQL possono essere usati nel linguaggio ospite ovunque sia permesso. Ogni variabile del compilatore di quel linguaggio, usata per passare argomenti ad un comando SQL, deve essere dichiarata in SQL.
| |
| − | Devono essere dichiarate alcune variabili speciali del linguaggio ospite. Vi sono due complicazione di cui tener conto:
| |
| − | i tipi di dati riconosciuti da SQL potrebbero non essere riconosciuti dal linguaggio ospite, e viceversa,
| |
| − | SQL è orientato agli insiemi, quindi si passa all’uso dei cursori. I comandi operano su tabelle e producono tabelle, cioè insiemi.
| |
| − | I comandi possono far riferimento a variabili definite nel programma ospite, queste però devono essere precedute da due punti (:) nei comandi SQL, e devono essere dichiarate tra i comandi EXEC SQL BEGIN DECLARE SECTION ed EXEC SQL END DECLARE SECTION.
| |
| − | Si può pensare ad un cursore come se “puntasse” ad una riga nella collezione di risposte dell’interrogazione cui è associato. Quando un cursore viene aperto si posiziona appena prima della prima riga. Possiamo usare il comando FETCH per leggere la prima riga del cursore nelle variabili del linguaggio ospite.
| |
| − | Quando questo viene eseguito, il cursore viene posizionato per puntare alla riga successiva( che è la prima riga della tabella quando FETCH è eseguito per la prima volta dopo l’apertura del cursore) e i valori delle colonne nella riga sono copiarti nelle corrispondenti variabili ospiti. Eseguendo ripetutamente questo comando FETCH possiamo leggere tutte le righe calcolate dall’interrogazione, una alla volta.
| |
| − | Quando abbiamo finito col cursore usiamo il comando CLOSE.
| |
| − | Proprietà dei cursori, la forma generale della dichiarazione di un cursore è:
| |
| − | DECLARE nome_cursore [INSENSITIVE] [SCROLL] CURSOR
| |
| − | [WITH HOLD]
| |
| − | FOR qualche interrogazione
| |
| − | [ORDER BY lista-ordinamento]
| |
| − | [FOR READ ONLY | FOR UPDATE]
| |
| − | Un cursore può essere dichiarato di sola lettura (FOR READ ONLY) oppure, se è definito su una relazione di base o una vista aggiornabile(FOR UPDATE).
| |
| − | Se è aggiornabile, semplici varianti dei comandi UPDATE e DELETE ci permettono di aggiornare o cancellare la riga su cui il cursore è posizionato
| |
| − | Un cursore è aggiornabile per default a meno che nella sua definizione sia stato specificato SCROLL e INSENSITIVE, nel qual caso è di sola lettura.
| |
| − | SCROLL;il cursore è scorrevole, quindi le varianti del comando FETCH possono essere usate per posizionarlo in maniera molto flessibile; altrimenti è consentito il solo comando FETCH di base, che sposta il cursore alla riga successiva.
| |
| − | INSENSITIVE;il cursore si comporta come se si muovesse su una copia privata della collezione di righe della risposta. Altrimenti per impostazione predefinita, le azioni di qualche altra transazione potrebbero modificare tali righe, creando comportamenti non prevedibili.
| |
| − | Un cursore mantenibile viene specificato con la clausola WITH HOLD, e non è chiuso quando la transazione termina. Se una qualunque transazione viene interrotta il sistema, potenzialmente, deve rifare parecchio lavoro. Quindi l’alternativa è spezzare la transazione in diverse transazioni, più piccole, ma ricordare la posizione nella tabella è complicato e soggetto a errori.
| |
| − | ORDER BY; può essere usata per specificare un ordinamento. La lista-ordinamento è una lista di voci di ordinamento(nome di colonna), eventualmente seguito da una delle parole chiave ASC e DESC. Ogni colonna menzionata nella clausola ORDER BY deve apparire anche nella lista-selezione dell’interrogazione associata al cursore; altrimenti non è chiaro su quali colonne effettuare l’ordinamento.
| |
| − | SQL dinamico; i due comandi principali sono PREPARE e EXECUTE:
| |
| − | char c_stringaSQL[] = {“DELETE FROM Velisti WHERE esperienza > 5”};
| |
| − | EXEC SQL PREPARE pronto FROM: c_stringaSQL;
| |
| − | EXE SQL EXECUTE pronto;
| |
| − | 1)il primo comando dichiara la variabile C c_stringaSQL e ne imposta il valore ad una rappresentazione stringa di un comando di SQL.
| |
| − | 2)la seconda istruzione fa sì che tale stringa venga esaminata e compilata come comando SQL, con l’eseguibile risultante legato alla variabile pronto
| |
| − | 3)la terza istruzione esegue il comando.
| |
| − | La preparazione di un comando SQL dinamico avviene durante l’esecuzione, che ne risulta appesantita. I comandi dell’SQL interattivo e dell’SQL incapsulato possono essere preparati una volta per tutte al momento della compilazione, e poi ri-eseguiti quanto si vuole. Di fatti si deve limitare l’uso dell’SQL dinamico a quelle situazioni in cui è essenziale.
| |
| − | | |
| − | ==MIR SYSTEM==
| |
| − | | |
| − | Lo scopo di questi sistemi è di permettere a qualsiasi utente di eseguire ricerche su tutta la musica esistente, attraverso interfacce con cui poter sottomettere al sistema descrizioni esaustive, nel modo più naturale possibile fornendo applicazioni utili a collegare e manipolare l’informazione ritornata dal sistema.
| |
| − | L’informazione musicale può essere descritta attraverso sette aspetti(Downie);
| |
| − | 1.Pitch Facet; la qualità del suono percepita che è principalmente una funzione della sua frequenza fondamentale.
| |
| − | Rappresentazione del pitch:
| |
| − | note sul pentagramma,
| |
| − | nome A, B,C#,
| |
| − | pitch class number 0, 1, 2,
| |
| − | solfeggio do, re mi.
| |
| − | Intervallo: è la differenza tra due pitch espressa in semitoni o attraverso la sua caratteristica tonale determinata dalla posizione dei due pitch nella sintassi tradizionale.
| |
| − | Melodia: insieme di pitch o intervalli percepiti in modo sequenziale bel tempo.
| |
| − | Chiave: viene considerato come sub-aspetto del pitch. I due contorni melodici sono presi percettivamente equivalenti, nonostante il fatto che sia diverso il loro pitch assoluto.
| |
| − | Contorno melodico: il pattern degli intervalli.
| |
| − | 2.Temporal Facet: informazione relativa alla durata degli eventi musicali che include:
| |
| − | i.Metrica
| |
| − | ii.Indicatori di tempo
| |
| − | iii.Durata del pitch
| |
| − | iv.Accenti
| |
| − | v.Durata armonica
| |
| − | Questi elementi costituiscono la parte ritmica del brano(questo può essere rappresentato in diversi modi, ognuno dei quali definisce uno stesso risultato)
| |
| − | Pause: possono essere considerate indicatori della durata degli eventi musicali che non contengono pitch.
| |
| − | Informazione temporale: può essere:
| |
| − | Assoluta ( metronomo ),
| |
| − | Generale ( adagio, forte ),
| |
| − | Relativo ( schneller, langsamer ),
| |
| − | Temporal distorsion ( rubato, rallentando ).
| |
| − | 3.Harmonic Facet: quando due o più pitch suonano simultaneamente, definita anche come polifonia. Interazione tra pitch e aspetto temporale per creare la polifonia ( caratteristica fondamentale della musica occidentale).
| |
| − | Gli eventi armonici , sebbene presenti nella partitura, non solo sempre indicati esplicitamente. La mente umana può percepire un accordo, nonostante la presenza di note “extra”.
| |
| − | 4.Timbral Facet: comprende tutti gli aspetti del colore del tono. La distinzione tra una nota suonata da un flauto ed un clarinetto è causata dalla differenza del timbro. Fanno parte di questo aspetto le informazioni sulla composizione dell’orchestra, e anche l’enumerazione degli strumenti.
| |
| − | 5.Editorial Facet: istruzioni sull’esecuzione( diteggiatura, ornamenti, istruzioni dinamiche, etc…). Anche la musica stessa può essere inclusa.
| |
| − | 6.Textual Facet: è l’aspetto più indipendente dalla melodia e dagli arrangiamenti associati. Un frammento di lirica in alcuni casi non è sufficiente per ritrovare il brano ricercato e viceversa.
| |
| − | 7.Bibliographic Facet: sono informazioni relative a:
| |
| − | titolo
| |
| − | compositore
| |
| − | arrangiatore
| |
| − | editore
| |
| − | numero di catalogo
| |
| − | data pubblicazione
| |
| − | esecutori.
| |
| − | Uno degli obbiettivi principali del MIR è permettere l’organizzazione dei dati per recuperare tutta l’informazione disponibile riguardante un certo brano musicale.
| |
| − | Interrogazioni per contenuto: confronto tra i complessi contenuti musicali presenti nella base di dati e contenuti musicali meno complessi introdotti come criterio di ricerca.
| |
| − | Per la costruzione di un DB musicale vi son tre passi:
| |
| − | 1.individuare lo scopo dei dati. In questa fase è necessario definire come le informazioni devono essere collezionate ed inserite nel DB, quali relazioni esistono tra loro e quali tipi di interrogazioni rendere disponibili all’utente finale.
| |
| − | 2.elencare i dati necessari, considerando le sorgenti d’informazione disponibili. Le informazioni testuali sono solitamente più ricche e frequenti di quelle multimediali a causa delle problematiche legate al copy-right.
| |
| − | 3.definire la miglior struttura per questo corpo. In pratica come le informazioni vengono classificate ed organizzate, o qual è il miglior standard con cui scrivere queste informazioni.
| |
| − | Senza una buona struttura l’uso e l’accesso del DB diventa inutile e complicato, la sua efficienza ne risente come la sua manutenzione.
| |
| − | Una volta definito il DB è necessario definire le interfacce e le tipologie d’interrogazione da fornire all’utente. Vi son tre tipi di ricerca:
| |
| − | Browsing: può essere un mezzo utile per cercare in un sistema ricco di collegamenti tra i dati ed i metadati, e permette di passare da un brano all’altro attraverso diversi collegamenti,
| |
| − | Textual search: indicizzazione di tutte le informazioni testuali accademiche( autore, titolo, …) e non accademiche( genere, frammenti delle liriche, …).
| |
| − | Search by content: interrogazioni basate sulla melodia o altri aspetti del contenuto audio.
| |
| − | Naturalmente si possono combinare le varie tipologie di ricerca per aumentare la potenza e l’efficienza del sistema.
| |
| − | La maniera di mostrare i risultati cambia l’utilità e le manipolazioni possibili dei dati restituiti dal sistema. I dati restituiti devono essere sufficienti a riconoscere quale brano nella lista dei risultati è quello ricercato, e una volta riconosciuto l’utente deve poter accedere a tutte le informazioni collegate, suddivise per tipologia( informazioni di catalogo e testuali, link ai meta-dati, link ad altri oggetti musicali).
| |
| − | Un altro aiuto nella ricerca sono le informazioni di catalogo che limitano la ricerca alla sola musica conosciuta. Uno dei più grandi e potenti descrittori usati dai consumatori di musica è il genere musicale, difatti due brani appartenenti allo stesso genere musicale hanno molti più elementi in comune rispetto a due brani non appartenenti allo stesso genere.
| |
| − | Generalmente gli strumenti musicali aiutano a definire il genere.
| |
| − | Catalog information: sono le informazioni che descrivono i brani musicali, non strettamente correlate al contenuto musicale. Descrivono chi ha preso parte alla realizzazione del brano, dove è stato registrato, informazioni sul supporto e sul copyright.
| |
| − | Multimedia characteristics: son metadadata che descrivono qualcosa di strettamente legato al contenuto musicale, e le informazioni associate col ricordo del frammento usato nella query-by-content.
| |
| − | Per valutare un sistema MIR si deve controllare che sia molto efficiente ed affidabile.
| |
| − | Per affidabilità intendiamo che il sistema deve permetter di trovare tutte e sole le informazioni richieste dall’utente. Queste devono essere sempre corrette( da verificare quando i dati sono elaborati automaticamente).
| |
| − | La complessità dei sistemi MIR è dovuta soprattutto all’enorme quantità di oggetti musicali.
| |
| − | Query by content: servono a trovare un brano di cui non si conoscono informazioni quali il titolo, l’autore, o altri metadata sufficienti per individuarlo. Usato anche per il copyright in modo da capire se un brano è molto simile ad un altro.
| |
| − | Verifica se un brano appena composto da un autore si frutto della creatività dell’artista e non influenzato da uno ascoltato in passato e poi dimenticato.
| |
| − | Il criterio su cui si basa la query-by-content è il frammento musicale, e di fatti vengono usati due tipi di DB:
| |
| − | a frammenti tematici: contengono frammenti che rappresentano i tempi musicali presenti nei brani. Il tema in questo caso viene considerato come una sequenza di note ripetuta diverse volte all’interno della composizione musicale. Una sequenza di note invece è considerata un tema se nella composizione esistono altre sequenze ottenute da questo attraverso qualche operatore musicale,
| |
| − | database di intere partiture: sono presenti tutte le melodie contenute in tutte le voci dell’intera partitura, perché un utente potrebbe ricordare un solo frammento del brano non appartenente al tema.
| |
| − | Query-by-humming, può risultare non accurata ed è per utenti non esperti.
| |
| − | L’approccio per questo metodo sono di due tipi:
| |
| − | DSP: elaborazione della forma d’onda o delle frequenze per trovare similarità tra i brani. Vi è una trasformazione in simbolico, dove vengono estrapolate le caratteristiche descriventi gli eventi musicali. Questo sistema risulta molo faticoso e complesso.
| |
| − | Simbolico: trasformazione dei brani in sequenze di stringhe di caratteri rappresentanti le sequenza melodiche contenute nei brani. Il frammento della query viene trasformato allo stesso modo e quindi confrontato con le stringhe nel DB.
| |
| − | Come criterio per le query-by-content viene usato l’audio( si definisce attraverso l’analisi delle frequenze esistenti nello spettro del segnale in ogni istante di tempo(discreto) il corrispondente pitch).
| |
| − | In input avremo un frammento audio(non strutturato per definizione) ed in output le caratteristiche capaci di definire i note-pattern.
| |
| − | Vi son dei problemi legati alla trascrizione da audio a simbolico:
| |
| − | Note segmentation: dove sono posizionate esattamente le note?Quanto durano?
| |
| − | Pitch variation della nota suonata: come individuare l’esatta altezza della nota suonata?
| |
| − | Note quantization: come posizionare le altezze sulle scale musicali?
| |
| − | Purtroppo viene difficile capire quale nota deve essere associata all’altezza del suono, infatti non esiste sempre una corrispondenza esatta.
| |
| − | Lo stesso discorso vale per la rappresentazione simbolica, infatti esistono molte tipologie del formato. Possiamo avere casi dove la stessa altezza viene rappresentata in più modi diversi o il nome della nota può rappresentare più altezze(di differenti ottave).
| |
| − | Sequenze di note: ogni elemento della sequenza è descritto da qualche parametro ( solitamente nome e durata della nota ).
| |
| − | Rappresentazione:
| |
| − | tutte le rappresentazioni della stessa nota vengono collassate in una sola,
| |
| − | l’alfabeto di 12 elementi, viene usato per rappresentare e dividere le altezze in semitoni,
| |
| − | questo però comporta una perdita d’informazione sul contorno melodico.
| |
| − | Trasposizione: gli algoritmi per calcolare la similarità vengono applicati 12 volte su ogni sequenza. Viene usato questo metodo nei sistemi dove l’elaborazione è limitata agli incipit
| |
| − | Sequenza d’intervalli: distanza tra due note adiacenti misurata in semitoni. La sequenza melodica è data dalla sequenza delle distanze tra un elemento e il suo successore. Come risultato si ha un perdita della nozione di nota come elemento d’ottava.
| |
| − | È anche dimostrato che l’uomo ascoltando un brano non ha l’esatta percezione dell’altezza delle note, ma ricorda più facilmente la sequenza degli intervalli.
| |
| − | Contorno melodico: si considera solo la direzione tra una nota ed il suo successore. È possibile rappresentare la sequenza melodica con solo 3 simboli: up, down, equal to.
| |
| − | Questo però permette di avere una trascrizione di query-by-humming corretta, e se la melodia è abbastanza lunga è possibili individuare univocamente il brano cercato.
| |
| − | La lunghezza media di un query fragment è pari a 7 note, significa ottenere centinaia di brani simili, impossibili ascoltarli tutti per trovare quello corretto.
| |
| − | Però questo sistema è utile come operazione di “pre-processing”, per scremare il contenuto del DB prima di usare un metodo più sofisticato.
| |
| − | Classi di equivalenza: ogni simbolo rappresenta n intervalli.
| |
| − | C1:ogni simbolo rappresenta un intervallo,
| |
| − | C3: ogni simbolo rappresenta 3 diversi intervalli adiacenti,
| |
| − | CU: tutti gli intervalli crescenti e decrescenti collassato in due differenti classi( contorno melodico ).
| |
| − | Rappresentazione Frame-based:
| |
| − | non si ha la segmentation, in pratica non si divide ogni singolo evento della melodia,
| |
| − | il tempo viene diviso in frame di ugual misura,
| |
| − | viene stimato il valore di un pitch per ogni frame,
| |
| − | le note non sono esplicitamente descritte,
| |
| − | in un unico valore sono rappresentabili le informazioni relative ad altezza e durata.
| |
| − | Svantaggio di questo metodo è che si perde l’informazione relativa al ritmo.
| |
| − | Music psychology: c’è un alta probabilità che qualche errore si presente nel frammento dell’interrogazione, di fatti anche utenti esperti possono non essere in grado di rappresentare in modo esatto la melodia del brano che stanno cercando.
| |
| − | L’interrogazione è distribuita su più voci:
| |
| − | non è sempre detto che il frammento della query rappresenti in modo esatto la melodia del brano che si sta cercando,
| |
| − | in punti adiacenti del brano, l’utente potrebbe ricordarsi la melodia di differenti parti, costruendo una nuova melodia.
| |
| − | Il concetto di similarità varia in funzione di:
| |
| − | memoria, che può essere a breve o lungo termine,
| |
| − | tipologia di utente, che va dal non esperto,al mediamente esperto e all’esperto.
| |
| − | Melodia: definire come una sequenza di note sia riconosciuta dall’uomo come una melodia di un brano polifonico.
| |
| − | String matching and melodic similarità: approccio tra i più utilizzati per risolvere il problema della similarità melodica. Una semplice formalizzazione del problema contestualizzato nell’ambito dello string matching potrebbe essere: sia f la stringa di caratteri che rappresenta il frammento melodico criterio di un’interrogazione e s la stringa di caratteri che rappresenta la partitura di un brano presente nel DB:
| |
| − | f è fattore di x?
| |
| − | se f non appare in x, quale sottoparte di f è presente in s?
| |
| − | quante volte un’approssimazione di f è presente in s?
| |
| − | Blast algorithm: Basic Local Alignment Search Tool: uno tra i metodi più efficaci utilizzati per l’elaborazione di database biologici. Permette d’individuare in due sequenze:
| |
| − | zone uguali o simili,
| |
| − | allineamenti globali.
| |
| − | Il grado di similarità tra le due sequenze mostra la correlazione. Questa può essere basata su:
| |
| − | Identità percentuale: numero di elementi uguali nello stesso ordine presenti nelle due sequenze rispetto al numero totale di elementi,
| |
| − | Conservazione: quando cambiando un elemento nella sequenza in una precisa posizione, le proprietà chimiche e fisiche restano invariate.
| |
| − | | |
| − | [[categoria:appunti]]
| |
Questa pagina è un copia-incolla poderoso degli appunti di El Conte, che li ha generosamente pubblicati su musicomio e che ringrazio infinitamente. L'impaginazione verrà sistemata al più presto e vedrò anche di integrare eventuali punti mancanti/carenti/non chiari, ammesso che ne trovi...
Promesso!
Introduzione
Il sistema informativo
Un sistema informativo è la componente (o il sottosistema) di una organizzazione che gestisce, acquisisce, elabora, conserva, produce, le informazioni di interesse, cioè utilizzate per il perseguimento degli scopi dell’organizzazione stessa.
Ogni organizzazione ha un sistema informativo, anche se può essere eventualmente non esplicitato nella struttura. Quasi sempre il sistema informativo è di supporto ad altri sottosistemi, e va quindi studiato nel contesto in cui è inserito. Inoltre è di solito suddiviso in sottosistemi (in modo gerarchico o decentrato), più o meno fortemente integrati tra loro.
Il sistema informatico è invece la parte del sistema informativo che gestisce informazioni per mezzo della tecnologia informatica.
La presenza di un sistema informatico all'interno di un sistema informativo non è obbligatoria: il concetto di “sistema informativo” è indipendente da qualsiasi automatizzazione. Esistono infatti organizzazioni la cui ragione d’essere è la gestione di informazioni (es: servizi anagrafici e banche) e che per secoli hanno operato senza l'ausilio dell'informatica.
Gestione delle informazioni
Nelle attività umane, le informazioni vengono gestite (registrate e scambiate) in forme diverse, a seconda delle necessità e capacità:
- idee informali
- linguaggio naturale (scritto o parlato, formale o colloquiale, in una lingua o in un’altra)
- disegni, grafici, schemi
- numeri
- codici (anche segreti)
E su vari supporti, dalla memoria umana alla carta.
Nelle attività standardizzate dei sistemi informativi complessi, sono state introdotte col tempo forme di organizzazione e codifica delle informazioni.
Ad esempio, nei servizi anagrafici si è iniziato con registrazioni discorsive e sono state poi introdotte informazioni via via più precise:
- nome e cognome
- estremi anagrafici
- codice fiscale
In particolare, nei sistemi informatici (e non solo in essi), le informazioni vengono rappresentate attraverso i dati.
Si dice informazione tutto ciò che produce variazioni nel patrimonio conoscitivo di un soggetto detto percettore dell'informazione.
Si dice dato una registrazione della descrizione di una qualsiasi caratteristica della realtà su un supporto che ne garantisca la conservazione e, mediante un insieme di simboli, ne garantisca la comprensibilità e la reperibilità.
Uno degli obiettivi fondamentali di un sistema di gestione dati è fornire un contesto interpretativo ai dati, in modo da consentire un accesso efficace alle informazioni da essi rappresentate.
Database e DBMS
Cosa sono
In un'accezione generica, un database è una collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni. In un'accezione più specifica, un database è una collezione di dati gestita da un DBMS.
Un DBMS (Database Management System) è un sistema (prodotto software) in grado di gestire collezioni di dati che siano:
- Grandi: di dimensioni (molto) maggiori della memoria centrale dei sistemi di calcolo utilizzati
- Persistenti: con un periodo di vita indipendentedalle singole esecuzioni dei programmi che le utilizzano
- Condivise: utilizzate da applicazioni diverse
Un DBMS deve garantire affidabilità (resistenza a malfunzionamenti hardware e software) e privatezza (mediante politiche di controllo degli accessi). Come ogni prodotto informatico, un DBMS deve essere efficiente, utilizzando al meglio le risorse di spazio e tempo del sistema, ed efficace, rendendo produttive le attività dei suoi utilizzatori.
La gestione di sistemi di dati grandi e persistenti è possibile anche tramite sistemi più semplici, quali gli ordinari file system dei sistemi operativi, che permettono di realizzare anche rudimentali forme di condivisione. I DBMS però estendono le funzionalità dei file system, fornendo più servizi ed in maniera integrata.
Caratteristiche
I maggiori vantaggi di un DBMS sono:
- l’indipendenza dei dati
- un loro accesso efficiente
- integrità e sicurezza
- amministrazione
- organizzazione degli accessi e ripristino da crash
- riduzione del tempo di sviluppo delle applicazioni.
Un DBMS è utile quando la quantità di dati è elevata e porterebbe ad un appesantimento operativo e/o quando si vogliono usare le sue potenzialità d’interrogazione dell’archivio di dati. Si dice transazione una qualunque esecuzione di un programma utenti in un DBMS.
Compito importante di un DBMS è la sequenzalizzazione di accessi concorrenti ai dati , così che ogni utente possa ignorare il fatto che altri stanno accedendo ai dati allo stesso tempo. Per fare ciò ci si serve di un meccanismo detto lock che serve a controllare l’acceso agli oggetti della base di dati. Un protocollo di locking è l'insieme di regole che ogni transazione deve seguire per garantire che l’effetto sia identico a quello ottenuto eseguendo tutte le transazioni in qualche ordine seriale.
Il DBMS mantiene un log di tutte le scritture sulla base di dati. Ogni azione di scrittura deve essere registrata prima di effettuare la modifica nella base di dati. Un WAL (write-ahead log) è usato nel caso il sistema andasse in crash appena fatto il cambiamento, ma prima che esso sia registrato nel log.
Un DBMS è dunque diviso in:
- Ottimizzatore d’interrogazioni che usa informazioni sulla memorizzazione dei dati per produrre un piano di esecuzione efficiente
- Piano di esecuzione, usato per valutare l’interrogazione
- Gestore dello spazio sul disco
- Gestore delle transazioni, assicura che le transazioni richiedano e rilascino i lock seguendo un buon protocollo di bloccaggio e programma l’esecuzione delle transazioni
- gestore dei lock, tiene traccia delle richieste dei lock
- gestore del ripristino, responsabile del mantenimento del log e del ripristino del sistema.
Un DBMS applica inoltre dei vincoli d’integrità, condizioni specificate dal DBA (Database Administrator) o dall’utente finale in uno schema di base dati, che limitano i dati memorizzabili in una istanza della base dati stessa. Ci sono vincoli statici (relativi ad uno stato della base di dati) e vincoli di transizione (relativi a stati diversi della base di dati).
Quando un’applicazione viene eseguita , il DBMS controlla se ci sono violazioni ai vincoli d'integrità e in quel caso non premette le modifiche ai dati.
Modelli di dati
Un modello di dati è un insieme di strumenti concettuali, o formalismo, che consta di tre componenti fondamentali:
- un insieme di strutture dati
- una notazione per specificare i dati tramite le strutture dati del modello
- un insieme di operazioni per manipolare i dati.
Generalmente si tratta di una struttura ad alto livello che nasconde molti dei dettagli di memorizzazione a basso livello. Un DBMS permette all’utente di definire i dati da memorizzare in termini di un modello di dati.
Un modello di dati semantico è un modello di dati ad alto livello che rende più semplice ad un utente creare una buona descrizione iniziale dei dati. Questi contengono una grande quantità di costrutti che aiutano a descrivere lo scenario di un’applicazione reale.
Al grado più elevato di astrazione troviamo i modelli concettuali, che permettono di rappresentare i dati in modo indipendente da ogni sistema, cercando di descrivere i concetti del mondo reale. Sono utilizzati nelle fasi preliminari di progettazione. Il più noto è il modello entità-relazione.
Scendendo di livello troviamo i modelli logici, utilizzati per l’organizzazione dei dati. Ad essi fanno riferimento i programmi, e sono indipendenti dalle strutture fisiche di memorizzazione. Ecco alcuni esempi di modelli logici: relazionale, reticolare, gerarchico, a oggetti...
E' importante che modelli simili favoriscano l'indipendenza dei dati. Tale proprietà si ottiene quando le applicazioni sono isolate dalle modifiche al modo in cui i dati sono strutturati e memorizzati.
Vi sono due tipi d’indipendenza dei dati:
- logica: i cambiamenti della struttura logica dei dati possono essere resi trasparenti agli utenti , cosi come la scelta delle relazioni da memorizzare
- fisica: lo schema logico isola gli utenti dai cambiamenti nei dettagli fisici di registrazione.
Il modello relazionale
Cos'è
Il modello relazionale è il modello logico più noto ed è quello che viene solitamente implementato in un DBMS. E' stato proposto da E. F. Codd nel 1970 per favorire l’indipendenza dei dati e reso disponibile in DBMS reali nel 1981. Si basa sul concetto matematico di relazione, questo fornisce al modello una base teorica che permette di dimostrare formalmente proprietà di dati e operazioni.
Una relazione consiste in uno schema relazionale e nelle sue istanze di relazione. Lo schema specifica il nome della relazione, il nome di ogni campo (o attributo), ed il dominio di ciascun campo. Un'istanza di relazione è la "realizzazione concreta" dello schema relazionale e può essere vista come una tabella con righe, dette tuple o record, divise nei campi contenenti i dati. I campi di ciascuna tupla devono corrispondere per numero e tipo ai campi dello schema relazionale.
Il grado di una relazione è il numero dei campi presenti. La cardinalità di un'istanza di relazione è il numero di tuple in essa.
Una collezione d'istanze di relazione, una per ogni schema di relazione nello schema di una base di dati relazionale, forma un'istanza della base di dati.
Vincoli di integrità
Affinché uno schema relazionale sia valido è necessario che le tuple nelle sue istanze siano univocamente identificabili. In altre parole, non possono esistere in un'istanza tuple con valori identici in tutti i loro campi.
Il vincolo di chiave è l’imposizione che un certo sottoinsieme dei campi di una relazione sia un identificatore unico per una tupla. Tale insieme deve inoltre essere minimale, Ovvero non possono esistere sottoinsiemi propri dell'insieme selezionato che siano a loro volta identificatori unici di una tupla. Un insieme di campi di questo tipo si chiama chiave candidata per la relazione, o più semplicemente chiave.
Ogni relazione ha una chiave, e l’insieme di tutti i campi è una sottochiave. Possono esserci più chiavi candidate per una relazione, in tal caso se il DBMS non supporta chiavi multiple si indica come chiave primaria la chiave scelta per l'identificazione univoca delle tuple. Nella scelta di una chiave primaria è meglio usarne una che viene usata più frequentemente nelle interrogazioni.
Si può far riferimento ad una tupla in qualunque parte della base di dati memorizzando i valori dai campi della sua chiave primaria. In particolare, se una relazione R ha un insieme di attributi che costituisce la chiave di una relazione R', allora tale insieme è una chiave esterna di R su R'. Queste chiavi permettono di collegare tra loro tuple di relazioni diverse e costituiscono un meccanismo, per valore, per modellare le associazioni tra relazioni.
Una chiave esterna deve essere uguale alla chiave primaria della relazione referenziata, cioè deve avere lo stesso numero di colonne e tipi di dati compatibili, sebbene i nomi delle colonne possano essere diversi.
L'integrità referenziale rappresenta un importante vincolo d’integrità semantica. Difatti se una tupla t riferisce come valori di una chiave esterna i valori V1,...,Vn, allora deve esistere nella relazione riferita una tupla t' con valori di chiave V1,...,Vn. In altre parole, affinché vi sia un corretto riferimento tra due tuple, i valori della chiave primaria e della chiave esterna devono essere identici e coerenti tra loro.
Algebra relazionale
L'algebra relazionale è il linguaggio formale di interrogazione associato al modello relazionale. Le interrogazioni sono composte usando una collezione di operatori. Ognuno di questi deve accettare istanze di relazione come argomenti e restituisce un’istanza di relazione come risultato.
Un’espressione di algebra relazionale è ricorsivamente definita come una relazione, un operatore algebrico unario applicato ad una singola espressione o un operatore algebrico binario applicato a due espressioni.
Ogni interrogazione relazionale descrive una procedura passo-passo per calcolare la risposta desiderata, basandosi sull’ordine in cui gli operatori sono in essa applicati.
- Selezione
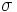 : l’operatore di selezione specifica le tuple da mantenere attraverso una condizione di selezione. Questa è una combinazione booleana di termini che hanno la forma attributo op costante oppure attributo1 op attributo2, dove op è uno degli operatori di confronto <,<=,=,=>,>,!=.
: l’operatore di selezione specifica le tuple da mantenere attraverso una condizione di selezione. Questa è una combinazione booleana di termini che hanno la forma attributo op costante oppure attributo1 op attributo2, dove op è uno degli operatori di confronto <,<=,=,=>,>,!=.
- Proiezione
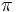 : l’operatore di proiezione invece ci permette di estrarre colonne da una relazione.
: l’operatore di proiezione invece ci permette di estrarre colonne da una relazione.
Le operazioni possibili sugli insiemi sono:
- Unione: R
 S restituisce un’istanza di relazione contenente tutte le tuple presenti nell’istanza di relazione R oppure S. Due istanze sono dette compatibili rispetto all’unione quando hanno lo stesso numero di campi e quando campi corrispondenti hanno lo stesso dominio.
S restituisce un’istanza di relazione contenente tutte le tuple presenti nell’istanza di relazione R oppure S. Due istanze sono dette compatibili rispetto all’unione quando hanno lo stesso numero di campi e quando campi corrispondenti hanno lo stesso dominio.
- Intersezione: R
 S restituisce un’istanza contenente tutte le tuple presenti sia in R che in S
S restituisce un’istanza contenente tutte le tuple presenti sia in R che in S
- Differenza: R - S restituisce un’istanza contenente tutte le tuple presenti in R ma non in S. Le relazioni devono essere compatibili all’unione, e lo schema del risultato è identico a R
- Prodotto cartesiano: R x S restituisce un’istanza di relazione il cui schema contiene tutti i campi di R seguiti da tutti i campi di S. Il risultato di R x S contiene una tupla |r,s|.
- Rinomina
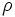 : usato per rinominare le tabelle.
: usato per rinominare le tabelle.
- Join: usato per combinare informazioni da due o più relazioni. Un predicato di join esprime una relazione che deve essere verificata dalle tuple risultato dell’interrogazione. Vi sono diversi tipi di join:
- Join condizionale: la versione più generale dell’operatore di join accetta una condizione di join c e un paio di istanze di relazione come argomenti, restituendo un’istanza di relazione.
- Equijoin: lo si ha quando la condizione di join consiste solamente di uguaglianze della forma R.nome1 = S.nome2. In questo caso mantenere entrambi gli attributi sarebbe ridondante. Per le condizioni di join che contengono solo queste uguaglianze l’operazione di join è completata con una ulteriore proiezione in cui S.nome2 viene scartato. Lo schema del risultato di un equijoin contiene i campi di R, seguiti dai campi di S che non appaiono condizioni di join.
- Join naturale: è un equijoin in cui le uguaglianze sono specificate su tutti i campi aventi lo stesso nome in R e S. Questo tipo di join gode della proprietà per cui il risultato è certamente privo di coppie di campi con lo stesso nome.
- Join esterni (pg99): questi si basano sui valori null, aggiungono al risultato le tuple R e S che non hanno partecipato al join, completandole con NULL. La forma è R OUTER JOIN S. Esistono diverse varianti dell’OUTER JOIN:
- FULL: sia le tuple di R che quelle di S che non partecipano al join vengono completate ed inserite nel risultato,
- LEFT: le tuple di R che non partecipano al join vengono completate ed inserite nel risultato,
- RIGHT: le tuple S che non partecipano al join vengono completate ed inserite nel risultato.
- Cross join: Corrisponde al prodotto cartesiano. La sua forma è R CROSS JOIN S
- Divisione: l’operazione di divisione R / S è l’insieme di tutti valori di x (in forma di tuple unarie) tali che per ogni valore y in S ci sia una tupla |x,y| in R. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così:
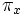 (((A) x B) – A).
(((A) x B) – A).
Progettazione di una base di dati
Analisi dei requisiti
Il primissimo passo nella progettazione è capire quali dati devono essere memorizzati, quali applicazioni devono essere costruite su di essi e quali operazioni sono più frequenti e soggette a requisiti prestazionali.
Per fare ciò vengono definite le caratteristiche della base di dati in maniera informale, mediante interviste con gli utenti,
analisi di altre basi di dati esistenti, normative, ambiente operativo ecc.
L’output è un documento in linguaggio naturale di specifica dei requisiti, che si possono suddividere in alcune categorie principali:
- Requisiti informativi: caratteristiche e tipologie dei dati
- Requisiti sulle operazioni: esplicitati nel carico di lavoro
- Requisiti sui vincoli di integrità ed autorizzazione: proprietà da assicurare ai dati, in termini di correttezza e protezione
- Requisiti sulla popolosità della base di dati: volume dei dati
Progettazione concettuale