Database Musicali/Appunti/2006-2007
Questa pagina è un copia-incolla poderoso degli appunti di El Conte, che li ha generosamente pubblicati su musicomio e che ringrazio infinitamente. L'impaginazione verrà sistemata al più presto e vedrò anche di integrare eventuali punti mancanti/carenti/non chiari, ammesso che ne trovi...
Promesso!
Indice
Introduzione
Il sistema informativo
Un sistema informativo è la componente (o il sottosistema) di una organizzazione che gestisce, acquisisce, elabora, conserva, produce, le informazioni di interesse, cioè utilizzate per il perseguimento degli scopi dell’organizzazione stessa.
Ogni organizzazione ha un sistema informativo, anche se può essere eventualmente non esplicitato nella struttura. Quasi sempre il sistema informativo è di supporto ad altri sottosistemi, e va quindi studiato nel contesto in cui è inserito. Inoltre è di solito suddiviso in sottosistemi (in modo gerarchico o decentrato), più o meno fortemente integrati tra loro.
Il sistema informatico è invece la parte del sistema informativo che gestisce informazioni per mezzo della tecnologia informatica.
La presenza di un sistema informatico all'interno di un sistema informativo non è obbligatoria: il concetto di “sistema informativo” è indipendente da qualsiasi automatizzazione. Esistono infatti organizzazioni la cui ragione d’essere è la gestione di informazioni (es: servizi anagrafici e banche) e che per secoli hanno operato senza l'ausilio dell'informatica.
Gestione delle informazioni
Nelle attività umane, le informazioni vengono gestite (registrate e scambiate) in forme diverse, a seconda delle necessità e capacità:
- idee informali
- linguaggio naturale (scritto o parlato, formale o colloquiale, in una lingua o in un’altra)
- disegni, grafici, schemi
- numeri
- codici (anche segreti)
E su vari supporti, dalla memoria umana alla carta.
Nelle attività standardizzate dei sistemi informativi complessi, sono state introdotte col tempo forme di organizzazione e codifica delle informazioni.
Ad esempio, nei servizi anagrafici si è iniziato con registrazioni discorsive e sono state poi introdotte informazioni via via più precise:
- nome e cognome
- estremi anagrafici
- codice fiscale
In particolare, nei sistemi informatici (e non solo in essi), le informazioni vengono rappresentate attraverso i dati.
Si dice informazione tutto ciò che produce variazioni nel patrimonio conoscitivo di un soggetto detto percettore dell'informazione.
Si dice dato una registrazione della descrizione di una qualsiasi caratteristica della realtà su un supporto che ne garantisca la conservazione e, mediante un insieme di simboli, ne garantisca la comprensibilità e la reperibilità.
Uno degli obiettivi fondamentali di un sistema di gestione dati è fornire un contesto interpretativo ai dati, in modo da consentire un accesso efficace alle informazioni da essi rappresentate.
Basi di dati e DBMS
Cosa sono
In un'accezione generica, un database è una collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni. In un'accezione più specifica, un database è una collezione di dati gestita da un DBMS.
Un DBMS (Database Management System) è un sistema (prodotto software) in grado di gestire collezioni di dati che siano:
- Grandi: di dimensioni (molto) maggiori della memoria centrale dei sistemi di calcolo utilizzati
- Persistenti: con un periodo di vita indipendentedalle singole esecuzioni dei programmi che le utilizzano
- Condivise: utilizzate da applicazioni diverse
Un DBMS deve garantire affidabilità (resistenza a malfunzionamenti hardware e software) e privatezza (mediante politiche di controllo degli accessi). Come ogni prodotto informatico, un DBMS deve essere efficiente, utilizzando al meglio le risorse di spazio e tempo del sistema, ed efficace, rendendo produttive le attività dei suoi utilizzatori.
La gestione di sistemi di dati grandi e persistenti è possibile anche tramite sistemi più semplici, quali gli ordinari file system dei sistemi operativi, che permettono di realizzare anche rudimentali forme di condivisione. I DBMS però estendono le funzionalità dei file system, fornendo più servizi ed in maniera integrata.
Caratteristiche
I maggiori vantaggi di un DBMS sono:
- l’indipendenza dei dati
- un loro accesso efficiente
- integrità e sicurezza
- amministrazione
- organizzazione degli accessi e ripristino da crash
- riduzione del tempo di sviluppo delle applicazioni.
Un DBMS è utile quando la quantità di dati è elevata e porterebbe ad un appesantimento operativo e/o quando si vogliono usare le sue potenzialità d’interrogazione dell’archivio di dati. Si dice transazione una qualunque esecuzione di un programma utenti in un DBMS.
Compito importante di un DBMS è la sequenzalizzazione di accessi concorrenti ai dati , così che ogni utente possa ignorare il fatto che altri stanno accedendo ai dati allo stesso tempo. Per fare ciò ci si serve di un meccanismo detto lock che serve a controllare l’acceso agli oggetti della base di dati. Un protocollo di locking è l'insieme di regole che ogni transazione deve seguire per garantire che l’effetto sia identico a quello ottenuto eseguendo tutte le transazioni in qualche ordine seriale.
Il DBMS mantiene un log di tutte le scritture sulla base di dati. Ogni azione di scrittura deve essere registrata prima di effettuare la modifica nella base di dati. Un WAL (write-ahead log) è usato nel caso il sistema andasse in crash appena fatto il cambiamento, ma prima che esso sia registrato nel log.
Un DBMS è dunque diviso in:
- Ottimizzatore d’interrogazioni che usa informazioni sulla memorizzazione dei dati per produrre un piano di esecuzione efficiente
- Piano di esecuzione, usato per valutare l’interrogazione
- Gestore dello spazio sul disco
- Gestore delle transazioni, assicura che le transazioni richiedano e rilascino i lock seguendo un buon protocollo di bloccaggio e programma l’esecuzione delle transazioni
- gestore dei lock, tiene traccia delle richieste dei lock
- gestore del ripristino, responsabile del mantenimento del log e del ripristino del sistema.
Un DBMS applica inoltre dei vincoli d’integrità, condizioni specificate dal DBA (Database Administrator) o dall’utente finale in uno schema di base dati, che limitano i dati memorizzabili in una istanza della base dati stessa. Ci sono vincoli statici (relativi ad uno stato della base di dati) e vincoli di transizione (relativi a stati diversi della base di dati).
Quando un’applicazione viene eseguita , il DBMS controlla se ci sono violazioni ai vincoli d'integrità e in quel caso non premette le modifiche ai dati.
Modelli di dati
Un modello di dati è un insieme di strumenti concettuali, o formalismo, che consta di tre componenti fondamentali:
- un insieme di strutture dati
- una notazione per specificare i dati tramite le strutture dati del modello
- un insieme di operazioni per manipolare i dati.
Generalmente si tratta di una struttura ad alto livello che nasconde molti dei dettagli di memorizzazione a basso livello. Un DBMS permette all’utente di definire i dati da memorizzare in termini di un modello di dati.
Un modello di dati semantico è un modello di dati ad alto livello che rende più semplice ad un utente creare una buona descrizione iniziale dei dati. Questi contengono una grande quantità di costrutti che aiutano a descrivere lo scenario di un’applicazione reale.
Al grado più elevato di astrazione troviamo i modelli concettuali, che permettono di rappresentare i dati in modo indipendente da ogni sistema, cercando di descrivere i concetti del mondo reale. Sono utilizzati nelle fasi preliminari di progettazione. Il più noto è il modello entità-relazione.
Scendendo di livello troviamo i modelli logici, utilizzati per l’organizzazione dei dati. Ad essi fanno riferimento i programmi, e sono indipendenti dalle strutture fisiche di memorizzazione. Ecco alcuni esempi di modelli logici: relazionale, reticolare, gerarchico, a oggetti...
E' importante che modelli simili favoriscano l'indipendenza dei dati. Tale proprietà si ottiene quando le applicazioni sono isolate dalle modifiche al modo in cui i dati sono strutturati e memorizzati.
Vi sono due tipi d’indipendenza dei dati:
- logica: i cambiamenti della struttura logica dei dati possono essere resi trasparenti agli utenti , cosi come la scelta delle relazioni da memorizzare
- fisica: lo schema logico isola gli utenti dai cambiamenti nei dettagli fisici di registrazione.
Progettazione di una base di dati
Analisi dei requisiti
Il primissimo passo nella progettazione è capire quali dati devono essere memorizzati, quali applicazioni devono essere costruite su di essi e quali operazioni sono più frequenti e soggette a requisiti prestazionali.
Per fare ciò vengono definite le caratteristiche della base di dati in maniera informale, mediante interviste con gli utenti, analisi di altre basi di dati esistenti, normative, ambiente operativo ecc.
L’output è un documento in linguaggio naturale di specifica dei requisiti, che si possono suddividere in alcune categorie principali:
- Requisiti informativi: caratteristiche e tipologie dei dati
- Requisiti sulle operazioni: esplicitati nel carico di lavoro
- Requisiti sui vincoli di integrità ed autorizzazione: proprietà da assicurare ai dati, in termini di correttezza e protezione
- Requisiti sulla popolosità della base di dati: volume dei dati
Progettazione concettuale
Le informazioni raccolte nel passo di analisi dei requisiti vengono usate per elaborare una descrizione ad alto livello dei dati da memorizzare.
Questo passo è sviluppato usando il modello entità-relazione, il quale fa parte di una famiglia di diversi modelli di dati ad alto livello, o semantici, usati nella progettazione delle basi di dati. Lo scopo è creare una semplice descrizione dei dati che approssimi il modo in cui utenti e sviluppatori pensano ad essi.
Progettazione logica
Bisogna poi scegliere un DBMS per implementare il progetto, e convertire la progettazione concettuale in uno schema nel modello del DBMS scelto. La traduzione non è sempre univoca.
Raffinamento dello schema
Si analizza l’insieme di relazioni dello schema relazionale per identificare potenziali problemi e per rifinirlo.
Progettazione fisica della base di dati
Si considerano i carichi di lavoro attesi che la nostra base di dati dovrà sopportare, e si raffina il progetto per garantire che esso soddisfi i criteri di prestazioni richieste.
Questo può consistere nella costruzione di indici su qualche tabella e nel raggruppamento di alcune tabelle, oppure può coinvolgere una riprogettazione sostanziale di intere parti dello schema ottenuto precedentemente.
Progettazione delle applicazioni e della sicurezza
Il modello relazionale
Cos'è
Il modello relazionale è il modello logico più noto ed è quello che viene solitamente implementato in un DBMS. E' stato proposto da E. F. Codd nel 1970 per favorire l’indipendenza dei dati e reso disponibile in DBMS reali nel 1981. Si basa sul concetto matematico di relazione, questo fornisce al modello una base teorica che permette di dimostrare formalmente proprietà di dati e operazioni.
Una relazione consiste in uno schema relazionale e nelle sue istanze di relazione. Lo schema specifica il nome della relazione, il nome di ogni campo (o attributo), ed il dominio di ciascun campo. Un'istanza di relazione è la "realizzazione concreta" dello schema relazionale e può essere vista come una tabella con righe, dette tuple o record, divise nei campi contenenti i dati. I campi di ciascuna tupla devono corrispondere per numero e tipo ai campi dello schema relazionale.
Il grado di una relazione è il numero dei campi presenti. La cardinalità di un'istanza di relazione è il numero di tuple in essa.
Una collezione d'istanze di relazione, una per ogni schema di relazione nello schema di una base di dati relazionale, forma un'istanza della base di dati.
Vincoli di integrità
Affinché uno schema relazionale sia valido è necessario che le tuple nelle sue istanze siano univocamente identificabili. In altre parole, non possono esistere in un'istanza tuple con valori identici in tutti i loro campi.
Il vincolo di chiave è l’imposizione che un certo sottoinsieme dei campi di una relazione sia un identificatore unico per una tupla. Tale insieme deve inoltre essere minimale, Ovvero non possono esistere sottoinsiemi propri dell'insieme selezionato che siano a loro volta identificatori unici di una tupla. Un insieme di campi di questo tipo si chiama chiave candidata per la relazione, o più semplicemente chiave.
Ogni relazione ha una chiave, e l’insieme di tutti i campi è una sottochiave. Possono esserci più chiavi candidate per una relazione, in tal caso se il DBMS non supporta chiavi multiple si indica come chiave primaria la chiave scelta per l'identificazione univoca delle tuple. Nella scelta di una chiave primaria è meglio usarne una che viene usata più frequentemente nelle interrogazioni.
Si può far riferimento ad una tupla in qualunque parte della base di dati memorizzando i valori dai campi della sua chiave primaria. In particolare, se una relazione R ha un insieme di attributi che costituisce la chiave di una relazione R', allora tale insieme è una chiave esterna di R su R'. Queste chiavi permettono di collegare tra loro tuple di relazioni diverse e costituiscono un meccanismo, per valore, per modellare le associazioni tra relazioni.
Una chiave esterna deve essere uguale alla chiave primaria della relazione referenziata, cioè deve avere lo stesso numero di colonne e tipi di dati compatibili, sebbene i nomi delle colonne possano essere diversi.
L'integrità referenziale rappresenta un importante vincolo d’integrità semantica. Difatti se una tupla t riferisce come valori di una chiave esterna i valori V1,...,Vn, allora deve esistere nella relazione riferita una tupla t' con valori di chiave V1,...,Vn. In altre parole, affinché vi sia un corretto riferimento tra due tuple, i valori della chiave primaria e della chiave esterna devono essere identici e coerenti tra loro.
Algebra relazionale
L'algebra relazionale è il linguaggio formale di interrogazione associato al modello relazionale. Le interrogazioni sono composte usando una collezione di operatori. Ognuno di questi deve accettare istanze di relazione come argomenti e restituisce un’istanza di relazione come risultato.
Un’espressione di algebra relazionale è ricorsivamente definita come una relazione, un operatore algebrico unario applicato ad una singola espressione o un operatore algebrico binario applicato a due espressioni.
Ogni interrogazione relazionale descrive una procedura passo-passo per calcolare la risposta desiderata, basandosi sull’ordine in cui gli operatori sono in essa applicati.
- Selezione
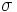 : l’operatore di selezione specifica le tuple da mantenere attraverso una condizione di selezione. Questa è una combinazione booleana di termini che hanno la forma attributo op costante oppure attributo1 op attributo2, dove op è uno degli operatori di confronto <,<=,=,=>,>,!=.
: l’operatore di selezione specifica le tuple da mantenere attraverso una condizione di selezione. Questa è una combinazione booleana di termini che hanno la forma attributo op costante oppure attributo1 op attributo2, dove op è uno degli operatori di confronto <,<=,=,=>,>,!=. - Proiezione
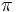 : l’operatore di proiezione invece ci permette di estrarre colonne da una relazione.
: l’operatore di proiezione invece ci permette di estrarre colonne da una relazione.
Le operazioni possibili sugli insiemi sono:
- Unione: R
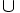 S restituisce un’istanza di relazione contenente tutte le tuple presenti nell’istanza di relazione R oppure S. Due istanze sono dette compatibili rispetto all’unione quando hanno lo stesso numero di campi e quando campi corrispondenti hanno lo stesso dominio.
S restituisce un’istanza di relazione contenente tutte le tuple presenti nell’istanza di relazione R oppure S. Due istanze sono dette compatibili rispetto all’unione quando hanno lo stesso numero di campi e quando campi corrispondenti hanno lo stesso dominio. - Intersezione: R
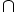 S restituisce un’istanza contenente tutte le tuple presenti sia in R che in S
S restituisce un’istanza contenente tutte le tuple presenti sia in R che in S - Differenza: R - S restituisce un’istanza contenente tutte le tuple presenti in R ma non in S. Le relazioni devono essere compatibili all’unione, e lo schema del risultato è identico a R
- Prodotto cartesiano: R x S restituisce un’istanza di relazione il cui schema contiene tutti i campi di R seguiti da tutti i campi di S. Il risultato di R x S contiene una tupla |r,s|.
- Rinomina
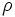 : usato per rinominare le tabelle.
: usato per rinominare le tabelle. - Join: usato per combinare informazioni da due o più relazioni. Un predicato di join esprime una relazione che deve essere verificata dalle tuple risultato dell’interrogazione. Vi sono diversi tipi di join:
- Join condizionale: la versione più generale dell’operatore di join accetta una condizione di join c e un paio di istanze di relazione come argomenti, restituendo un’istanza di relazione.
- Equijoin: lo si ha quando la condizione di join consiste solamente di uguaglianze della forma R.nome1 = S.nome2. In questo caso mantenere entrambi gli attributi sarebbe ridondante. Per le condizioni di join che contengono solo queste uguaglianze l’operazione di join è completata con una ulteriore proiezione in cui S.nome2 viene scartato. Lo schema del risultato di un equijoin contiene i campi di R, seguiti dai campi di S che non appaiono condizioni di join.
- Join naturale: è un equijoin in cui le uguaglianze sono specificate su tutti i campi aventi lo stesso nome in R e S. Questo tipo di join gode della proprietà per cui il risultato è certamente privo di coppie di campi con lo stesso nome.
- Join esterni (pg99): questi si basano sui valori null, aggiungono al risultato le tuple R e S che non hanno partecipato al join, completandole con NULL. La forma è R OUTER JOIN S. Esistono diverse varianti dell’OUTER JOIN:
- FULL: sia le tuple di R che quelle di S che non partecipano al join vengono completate ed inserite nel risultato,
- LEFT: le tuple di R che non partecipano al join vengono completate ed inserite nel risultato,
- RIGHT: le tuple S che non partecipano al join vengono completate ed inserite nel risultato.
- Cross join: Corrisponde al prodotto cartesiano. La sua forma è R CROSS JOIN S
- Divisione: l’operazione di divisione R / S è l’insieme di tutti valori di x (in forma di tuple unarie) tali che per ogni valore y in S ci sia una tupla |x,y| in R. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così:
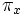 (((A) x B) – A).
(((A) x B) – A).