Differenze tra le versioni di "Database Musicali/Appunti/2006-2007"
(→Progettazione concettuale) |
(→Basi di dati e DBMS) |
||
| (13 versioni intermedie di un altro utente non mostrate) | |||
| Riga 3: | Riga 3: | ||
Promesso! | Promesso! | ||
| − | == | + | ==Sistemi informativi, basi di dati e DBMS== |
===Il sistema informativo=== | ===Il sistema informativo=== | ||
Un '''sistema informativo''' è la componente (o il sottosistema) di una organizzazione che gestisce, acquisisce, elabora, conserva, produce, le informazioni di interesse, cioè utilizzate per il perseguimento degli scopi dell’organizzazione stessa. | Un '''sistema informativo''' è la componente (o il sottosistema) di una organizzazione che gestisce, acquisisce, elabora, conserva, produce, le informazioni di interesse, cioè utilizzate per il perseguimento degli scopi dell’organizzazione stessa. | ||
| Riga 38: | Riga 38: | ||
Uno degli obiettivi fondamentali di un sistema di gestione dati è fornire un '''contesto interpretativo''' ai dati, in modo da consentire un accesso efficace alle informazioni da essi rappresentate. | Uno degli obiettivi fondamentali di un sistema di gestione dati è fornire un '''contesto interpretativo''' ai dati, in modo da consentire un accesso efficace alle informazioni da essi rappresentate. | ||
| − | ==Basi di dati e DBMS | + | ===Basi di dati e DBMS=== |
| − | |||
In un'accezione generica, un '''database''' è una collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni. In un'accezione più specifica, un database è una collezione di dati gestita da un DBMS. | In un'accezione generica, un '''database''' è una collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni. In un'accezione più specifica, un database è una collezione di dati gestita da un DBMS. | ||
Un '''DBMS''' (Database Management System) è un sistema (prodotto software) in grado di gestire collezioni di dati che siano: | Un '''DBMS''' (Database Management System) è un sistema (prodotto software) in grado di gestire collezioni di dati che siano: | ||
* '''Grandi:''' di dimensioni (molto) maggiori della memoria centrale dei sistemi di calcolo utilizzati | * '''Grandi:''' di dimensioni (molto) maggiori della memoria centrale dei sistemi di calcolo utilizzati | ||
| − | * '''Persistenti:''' con un periodo di vita | + | * '''Persistenti:''' con un periodo di vita indipendente dalle singole esecuzioni dei programmi che le utilizzano |
* '''Condivise:''' utilizzate da applicazioni diverse | * '''Condivise:''' utilizzate da applicazioni diverse | ||
| Riga 51: | Riga 50: | ||
La gestione di sistemi di dati grandi e persistenti è possibile anche tramite sistemi più semplici, quali gli ordinari file system dei sistemi operativi, che permettono di realizzare anche rudimentali forme di condivisione. I DBMS però estendono le funzionalità dei file system, fornendo più servizi ed in maniera integrata. | La gestione di sistemi di dati grandi e persistenti è possibile anche tramite sistemi più semplici, quali gli ordinari file system dei sistemi operativi, che permettono di realizzare anche rudimentali forme di condivisione. I DBMS però estendono le funzionalità dei file system, fornendo più servizi ed in maniera integrata. | ||
| − | ===Caratteristiche=== | + | ===Caratteristiche dei DBMS=== |
I maggiori vantaggi di un DBMS sono: | I maggiori vantaggi di un DBMS sono: | ||
* l’indipendenza dei dati | * l’indipendenza dei dati | ||
| Riga 128: | Riga 127: | ||
===Progettazione delle applicazioni e della sicurezza=== | ===Progettazione delle applicazioni e della sicurezza=== | ||
| + | |||
| + | ==Il modello entità-associazione (ER)== | ||
| + | ===Cos'è=== | ||
| + | Il '''modello entità-relazione''' è il modello concettuale più usato nella progettazione concettuale di una base di dati di tipo relazionale. E' dotato di un proprio diagramma, noto come '''diagramma ER''', che consente di rappresentare graficamente la struttura ad alto livello della base di dati. E' anche noto come '''modello entità-relazione''' (entity-relationship), ma useremo l'altra traduzione per non generare ambiguità con le caratteristiche del modello relazionale. | ||
| + | |||
| + | Il modello entità-associazione si basa su tre concetti fondamentali: quello di '''entità''', di '''attributo''' e di '''associazione''' (o relazione). | ||
| + | |||
| + | ===Entità=== | ||
| + | Un'entità è un oggetto nel mondo reale (concreto o astratto) che si distingue da altri progetti. Vi sono anche insiemi di entità, e questi non hanno bisogno di essere disgiunti. Un entità è anche un''''astrazione della realtà''' la cui informazione è indipendente dal dominio in cui l’entità è utilizzata. Invece un’istanza di entità sono specifici oggetti appartenenti ad una certa entità. | ||
| + | |||
| + | ===Attributi=== | ||
| + | Un’entità è descritta usando un insieme di attributi. Tutte le entità di un dato insieme hanno gli stessi attributi: questo è ciò che s’intende con simili. Viene chiamata attributo la coppia ''<nome_di_attributo, dominio>'' e ogni entità è caratterizzata da uno o più attributi. | ||
| + | |||
| + | Gli attributi possono essere monovalore (un solo valore memorizzato alla volta, es. l'età di una persona), multivalore (più valori possibili, es. gli esami sostenuti da uno studente) e compositi (es. un indirizzo, che è scomponibile iv via, n. civico, CAP e città). | ||
| + | |||
| + | Per ogni attributo associato ad un insieme di entità, dobbiamo definire un dominio di valori possibili. Vi son diversi tipi di domini: | ||
| + | * '''Semplice''': sono domini standard(interi, reali, booleani…), con intervalli ed insiemi di valori definiti per enumerazione dall’utente, | ||
| + | * '''Composti''': l’insieme dei valori è dato dal prodotto cartesiano degli insiemi di valori associati ai domini componenti. Servono per associare un dominio agli attributi composti. | ||
| + | Le informazioni sui domini di un attributo non sono direttamente rappresentabili in un diagramma ER, sono però fondamentali per una corretta progettazione logica. | ||
| + | |||
| + | Inoltre per ciascun insieme di entità useremo una '''chiave'''. Questa è un insieme minimale di attributi i cui valori identificano univocamente una entità dell’insieme. Potrebbe esserci più di una chiave candidata, e in questo caso ne designiamo una come '''chiave primaria'''. Una chiave non può avere valori nulli, in alcuni casi la chiave può essere soltanto una dove il sistema non permette di averne di più. | ||
| + | |||
| + | Gli attributi vengono rappresentati con degli '''ovali''', e se sono sottolineati sono delle chiavi primarie mentre le entità sono dei '''rettangoli'''. | ||
| + | |||
| + | ===Associazioni=== | ||
| + | Un''''associazione''' mette in relazione fra loro due o più entità. Come per le entità si può raccogliere un gruppo di associazioni simili in un insieme di associazioni. | ||
| + | |||
| + | Anche un'associazione può avere attributi che la descrivono, i quali son usati per registrare informazioni sulla relazione, piuttosto che su ciascuna delle entità partecipanti. | ||
| + | |||
| + | Un’istanza di un insieme di relazioni è un insieme di relazioni, questa può esser vista come una “fotografia” dell’insieme di relazioni di un certo istante. Gli insiemi di entità che partecipano ad una relazione non devono necessariamente essere distinti: qualche volta una relazione può coinvolgere entità dello stesso insieme. | ||
| + | |||
| + | Il '''ruolo''' è la funzione che un’istanza di entità esercita nell’ambito di un’associazione. Nel caso di un’associazione unaria il ruolo è sempre necessario (es. in un'associazione unaria che coinvolge due istanze dell'entità FILM, una avrà il ruolo di sequel e l'altra di "prequel"). | ||
==Il modello relazionale== | ==Il modello relazionale== | ||
| Riga 178: | Riga 209: | ||
** '''Cross join:''' Corrisponde al prodotto cartesiano. La sua forma è ''R CROSS JOIN S'' | ** '''Cross join:''' Corrisponde al prodotto cartesiano. La sua forma è ''R CROSS JOIN S'' | ||
* '''Divisione:''' l’operazione di divisione ''R / S'' è l’insieme di tutti valori di ''x'' (in forma di tuple unarie) tali che per ogni valore ''y'' in ''S'' ci sia una tupla ''|x,y|'' in ''R''. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così: ''<math>\pi_x</math>((<math>\pi_x</math>(A) x B) – A)''. | * '''Divisione:''' l’operazione di divisione ''R / S'' è l’insieme di tutti valori di ''x'' (in forma di tuple unarie) tali che per ogni valore ''y'' in ''S'' ci sia una tupla ''|x,y|'' in ''R''. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così: ''<math>\pi_x</math>((<math>\pi_x</math>(A) x B) – A)''. | ||
| + | |||
| + | ==MIR SYSTEM== | ||
| + | |||
| + | Lo scopo di questi sistemi è di permettere a qualsiasi utente di eseguire ricerche su tutta la musica esistente, attraverso interfacce con cui poter fornire al sistema descrizioni esaustive, nel modo più naturale possibile fornendo applicazioni utili a collegare e manipolare l’informazione ritornata dal sistema. | ||
| + | |||
| + | ===Descrizione dell'informazione musicale=== | ||
| + | L’informazione musicale può essere descritta attraverso sette aspetti (Downie): | ||
| + | |||
| + | ====Pitch Facet==== | ||
| + | Descrive la qualità del suono percepita che è principalmente una funzione della sua frequenza fondamentale. | ||
| + | |||
| + | Rappresentazione del pitch: | ||
| + | * note sul pentagramma | ||
| + | * nome (A, B, C...) | ||
| + | * pitch class number (0, 1, 2...) | ||
| + | * solfeggio (do, re, mi...) | ||
| + | |||
| + | '''Intervallo:''' è la differenza tra due pitch espressa in semitoni o attraverso la sua caratteristica tonale determinata dalla posizione dei due pitch nella sintassi tradizionale (quinta giusta, terza minore...). | ||
| + | |||
| + | '''Melodia:''' insieme di pitch o intervalli percepiti in modo sequenziale nel tempo. | ||
| + | |||
| + | '''Contorno melodico:''' il pattern degli intervalli. | ||
| + | |||
| + | '''Chiave:''' viene considerato come sub-aspetto del pitch. Due contorni melodici con pitch assoluto diverso ma con la medesima distribuzione di intervalli sono considerati percettivamente equivalenti (melodie trasposte). | ||
| + | |||
| + | ====Temporal Facet==== | ||
| + | Descrive l'informazione relativa alla durata degli eventi musicali che include: | ||
| + | # Metrica | ||
| + | # Indicatori di tempo | ||
| + | # Durata del pitch | ||
| + | # Accenti | ||
| + | # Durata armonica | ||
| + | |||
| + | Questi elementi costituiscono la parte ritmica del brano (questo può essere rappresentato in diversi modi, ognuno dei quali definisce uno stesso risultato). | ||
| + | |||
| + | '''Pause:''' possono essere considerate indicatori della durata degli eventi musicali che non contengono pitch. | ||
| + | |||
| + | L'informazione temporale può essere: | ||
| + | * Assoluta (metronomo ), | ||
| + | * Generale (adagio, forte ), | ||
| + | * Relativa (schneller, langsamer), | ||
| + | * Temporal distorsion (rubato, rallentando). | ||
| + | |||
| + | ====Harmonic Facet==== | ||
| + | Quando due o più pitch suonano simultaneamente, definita anche come polifonia. Interazione tra pitch e aspetto temporale per creare la polifonia (caratteristica fondamentale della musica occidentale). | ||
| + | |||
| + | Gli eventi armonici, sebbene presenti nella partitura, non sono sempre indicati esplicitamente. La mente umana può percepire un accordo, nonostante la presenza di note “extra”. | ||
| + | |||
| + | ====Timbral Facet==== | ||
| + | Comprende tutti gli aspetti del colore del tono. La distinzione tra una nota suonata da un flauto ed un clarinetto è causata dalla differenza del timbro. Fanno parte di questo aspetto le informazioni sulla composizione dell’orchestra, e anche l’enumerazione degli strumenti, ma non lo completano dal momento che tecniche esecutive diverse possono far generare al medesimo strumento timbri totalmente diversi (es. corda sfregata/martellata/pizzicata). | ||
| + | |||
| + | ====Editorial Facet==== | ||
| + | Istruzioni sull’esecuzione (diteggiatura, ornamenti, istruzioni dinamiche, etc). Tutta la partitura potrebbe essere inclusa in questo aspetto (le note stesse rappresentano istruzioni esecutive). Quasi sempre l'editorial facet non è codificato in maniera completa nella partitura, poiché viene completato dall'interpretazione personale dell'esecutore. | ||
| + | |||
| + | ====Textual Facet==== | ||
| + | E' l'aspetto più indipendente dalla melodia e dagli arrangiamenti associati. Un frammento di lirica in alcuni casi non è sufficiente per ritrovare il brano ricercato e viceversa, dal momento che potrebbero esserci più brani (o riarrangiamenti, o cover) che potrebbero far uso dello stesso testo. | ||
| + | |||
| + | ====Bibliographic Facet==== | ||
| + | A questo campo appartengono tutti i '''metadati''', informazioni aggiuntive relative al brano ma non contenute intrinsecamente in esso. Sono informazioni relative a: | ||
| + | * titolo | ||
| + | * compositore | ||
| + | * arrangiatore | ||
| + | * editore | ||
| + | * numero di catalogo | ||
| + | * data pubblicazione | ||
| + | * esecutori | ||
| + | |||
| + | ===Progettazione di un MIR system=== | ||
| + | Uno degli obiettivi principali del MIR è permettere l’organizzazione dei dati per recuperare tutta l’informazione disponibile riguardante un certo brano musicale. | ||
| + | |||
| + | Per la costruzione di un DB musicale vi sono tre passi: | ||
| + | # '''Individuare lo scopo dei dati'''. In questa fase è necessario definire come le informazioni devono essere collezionate ed inserite nel DB, quali relazioni esistono tra loro e quali tipi di interrogazioni rendere disponibili all’utente finale. | ||
| + | # '''Elencare i dati necessari''', considerando le sorgenti d’informazione disponibili. Le informazioni testuali sono solitamente più ricche e frequenti di quelle multimediali a causa delle problematiche legate al copyright. | ||
| + | # '''Definire la miglior struttura''' per questo corpo. In pratica come le informazioni vengono classificate ed organizzate, o qual è il miglior standard con cui scrivere queste informazioni. Senza una buona struttura l’uso e l’accesso del DB diventa inutile e complicato, la sua efficienza ne risente come la sua manutenzione. | ||
| + | |||
| + | Una volta definito il DB è necessario definire le interfacce e le tipologie d’interrogazione da fornire all’utente. Vi sono tre tipi di ricerca: | ||
| + | * '''Browsing:''' può essere un mezzo utile per cercare in un sistema ricco di collegamenti tra i dati ed i metadati, e permette di passare da un brano all’altro attraverso diversi collegamenti. | ||
| + | * '''Textual search:''' indicizzazione di tutte le informazioni testuali accademiche (autore, titolo...) e non accademiche (genere, frammenti delle liriche...). | ||
| + | * '''Search by content:''' confronto tra i complessi contenuti musicali presenti nella base di dati e contenuti musicali meno complessi introdotti come criterio di ricerca. queste interrogazioni sono generalmente basate sulla melodia o altri aspetti del contenuto audio. servono a trovare un brano di cui non si conoscono informazioni quali il titolo, l’autore, o altri metadata sufficienti per individuarlo. Usato anche per il copyright in modo da capire se un brano è molto simile ad un altro. | ||
| + | |||
| + | Naturalmente si possono combinare le varie tipologie di ricerca per aumentare la potenza e l’efficienza del sistema. | ||
| + | |||
| + | La maniera di mostrare i risultati cambia l’utilità e le manipolazioni possibili dei dati restituiti dal sistema. I dati restituiti devono essere sufficienti a riconoscere quale brano nella lista dei risultati è quello ricercato, e una volta riconosciuto l’utente deve poter accedere a tutte le informazioni collegate, suddivise per tipologia (informazioni di catalogo e testuali, link ai meta-dati, link ad altri oggetti musicali). | ||
| + | |||
| + | Un altro aiuto nella ricerca sono le informazioni di catalogo che limitano la ricerca alla sola musica conosciuta. Uno dei più grandi e potenti descrittori usati dai consumatori di musica è il genere musicale, difatti due brani appartenenti allo stesso genere musicale hanno molti più elementi in comune rispetto a due brani non appartenenti allo stesso genere. | ||
| + | |||
| + | Generalmente gli strumenti musicali aiutano a definire il genere. | ||
| + | |||
| + | '''Catalog information:''' sono le informazioni che descrivono i brani musicali, non strettamente correlate al contenuto musicale. Descrivono chi ha preso parte alla realizzazione del brano, dove è stato registrato, informazioni sul supporto e sul copyright. | ||
| + | |||
| + | '''Multimedia characteristics:''' sono metadadati che descrivono qualcosa di strettamente legato al contenuto musicale, e le informazioni associate col ricordo del frammento usato nella query-by-content. | ||
| + | |||
| + | ===Valutazione della qualità=== | ||
| + | Per valutare un sistema MIR si deve controllare che sia molto efficiente ed affidabile. | ||
| + | |||
| + | Per affidabilità intendiamo che il sistema deve permetter di trovare tutte e sole le informazioni richieste dall’utente. Queste devono essere sempre corrette (da verificare quando i dati sono elaborati automaticamente). | ||
| + | |||
| + | La complessità dei sistemi MIR è dovuta soprattutto all’enorme quantità di oggetti musicali. | ||
| + | |||
| + | ===Query by content=== | ||
| + | Il criterio su cui si basa la query-by-content è il frammento musicale. Per realizzare questo approccio vengono solitamente usati due tipi di DB: | ||
| + | * '''a frammenti tematici:''' contengono frammenti che rappresentano i tempi musicali presenti nei brani. Il tema in questo caso viene considerato come una sequenza di note ripetuta diverse volte all’interno della composizione musicale. Una sequenza di note invece è considerata un tema se nella composizione esistono altre sequenze ottenute da questo attraverso qualche operatore musicale. | ||
| + | * '''database di intere partiture:''' sono presenti tutte le melodie contenute in tutte le voci dell’intera partitura, perché un utente potrebbe ricordare un solo frammento del brano non appartenente al tema. | ||
| + | |||
| + | '''Sequenze di note:''' ogni elemento della sequenza è descritto da qualche parametro (solitamente nome e durata della nota). | ||
| + | |||
| + | '''Query-by-humming:''' il frammento musicale viene introdotto canticchiando o fischiettando la melodia da cercare. può risultare non accurata ed è per utenti non esperti. | ||
| + | |||
| + | Gli approcci per questo metodo sono di due tipi: | ||
| + | * '''DSP:''' elaborazione della forma d’onda o delle frequenze per trovare similarità tra i brani. Vi è una trasformazione in simbolico, dove vengono estrapolate le caratteristiche descriventi gli eventi musicali. Questo sistema risulta molo faticoso e complesso. | ||
| + | * '''Simbolico:''' trasformazione dei brani in sequenze di stringhe di caratteri rappresentanti le sequenze melodiche contenute nei brani. Il frammento della query viene trasformato allo stesso modo e quindi confrontato con le stringhe nel DB. | ||
| + | |||
| + | Come criterio per le query-by-content viene usato l’audio (si definisce attraverso l’analisi delle frequenze esistenti nello spettro del segnale in ogni istante di tempo discreto il corrispondente pitch). | ||
| + | In input avremo un frammento audio (non strutturato per definizione) ed in output le caratteristiche capaci di definire i note-pattern. | ||
| + | |||
| + | Vi sono dei problemi legati alla trascrizione da audio a simbolico: | ||
| + | * '''Note segmentation:''' dove sono posizionate esattamente le note? Quanto durano? | ||
| + | * '''Pitch variation''' della nota suonata: come individuare l’esatta altezza della nota suonata? | ||
| + | * '''Note quantization:''' come posizionare le altezze sulle scale musicali? | ||
| + | |||
| + | Purtroppo viene difficile capire quale nota deve essere associata all’altezza del suono, infatti non esiste sempre una corrispondenza esatta. | ||
| + | |||
| + | Lo stesso discorso vale per la rappresentazione simbolica, infatti esistono molte tipologie del formato. Possiamo avere casi dove la stessa altezza viene rappresentata in più modi diversi o il nome della nota può rappresentare più altezze (di differenti ottave). | ||
| + | |||
| + | A volte per ovviare a questi problemi, tutte le rappresentazioni della stessa nota vengono collassate in una sola. L’alfabeto di 12 elementi viene usato per rappresentare e dividere le altezze in semitoni, questo però comporta una perdita d’informazione sul contorno melodico. | ||
| + | Si applicano poi degli algoritmi di trasposizione per calcolare la similarità, 12 volte su ogni sequenza. Viene usato questo metodo nei sistemi dove l’elaborazione è limitata agli incipit. | ||
| + | |||
| + | ===Tecniche di conversione simbolica=== | ||
| + | '''Sequenza d’intervalli:''' distanza tra due note adiacenti misurata in semitoni. La sequenza melodica è data dalla sequenza delle distanze tra un elemento e il suo successore. Come risultato si ha un perdita della nozione di nota come elemento d’ottava. È dimostrato che l’uomo ascoltando un brano non ha l’esatta percezione dell’altezza delle note, ma ricorda più facilmente la sequenza degli intervalli. | ||
| + | |||
| + | '''Contorno melodico:''' si considera solo la direzione tra una nota ed il suo successore. È possibile rappresentare la sequenza melodica con solo 3 simboli: up, down, equal to. Questo però permette di avere una trascrizione di query-by-humming corretta, e se la melodia è abbastanza lunga è possibile individuare univocamente il brano cercato. | ||
| + | |||
| + | '''Rappresentazione Frame-based:''' | ||
| + | Non si ha la segmentation, in pratica non si divide ogni singolo evento della melodia. Il tempo viene diviso in frame di ugual misura, e viene stimato il valore di un pitch per ogni frame. Le note non sono esplicitamente descritte, in un unico valore sono rappresentabili le informazioni relative ad altezza e durata. Lo svantaggio di questo metodo è che si perde l’informazione relativa al ritmo. | ||
| + | |||
| + | La lunghezza media di un query fragment è pari a 7 note. Ciò significa ottenere centinaia di brani simili, impossibili da ascoltare tutti per trovare quello corretto. Questo sistema è però utile come operazione di “pre-processing”, per scremare il contenuto del DB prima di usare un metodo più sofisticato. | ||
| + | |||
| + | ===Criteri di similarità=== | ||
| + | '''Classi di equivalenza:''' ogni simbolo rappresenta n intervalli. | ||
| + | * '''C1:''' ogni simbolo rappresenta un intervallo, | ||
| + | * '''C3:''' ogni simbolo rappresenta 3 diversi intervalli adiacenti, | ||
| + | * '''CU:''' tutti gli intervalli crescenti e decrescenti collassato in due differenti classi (contorno melodico ). | ||
| + | |||
| + | '''Music psychology:''' c’è un alta probabilità che qualche errore sia presente nel frammento dell’interrogazione, difatti anche utenti esperti possono non essere in grado di rappresentare in modo esatto la melodia del brano che stanno cercando. Inoltre, non è sempre detto che il frammento della query rappresenti in modo esatto la melodia del brano che si sta cercando, in punti adiacenti del brano, l’utente potrebbe ricordarsi la melodia di differenti parti, costruendo una nuova melodia.el caso di brani polifonici poi, bisogna definire come una sequenza di note sia riconosciuta dall’uomo come una melodia in mezzo alle altre voci. | ||
| + | |||
| + | Il concetto di similarità varia in funzione di: | ||
| + | * '''memoria''', che può essere a breve o lungo termine, | ||
| + | * '''tipologia di utente''', che va dal non esperto,al mediamente esperto e all’esperto. | ||
| + | |||
| + | '''String matching and melodic similarity:''' approccio tra i più utilizzati per risolvere il problema della similarità melodica. Una semplice formalizzazione del problema contestualizzato nell’ambito dello string matching potrebbe essere: sia ''f'' la stringa di caratteri che rappresenta il frammento melodico criterio di un’interrogazione e ''s'' la stringa di caratteri che rappresenta la partitura di un brano presente nel DB: | ||
| + | * ''f'' è fattore di ''x''? | ||
| + | * se ''f'' non appare in ''x'', quale sottoparte di ''f'' è presente in ''s''? | ||
| + | * quante volte un’approssimazione di ''f'' è presente in ''s''? | ||
| + | |||
| + | '''Blast algorithm:''' Basic Local Alignment Search Tool, uno tra i metodi più efficaci utilizzati per l’elaborazione di database biologici. Permette d’individuare in due sequenze zone uguali o simili e allineamenti globali. | ||
| + | |||
| + | Il grado di similarità tra le due sequenze mostra la correlazione. Questa può essere basata su: | ||
| + | * '''Identità percentuale:''' numero di elementi uguali nello stesso ordine presenti nelle due sequenze rispetto al numero totale di elementi. | ||
| + | * '''Conservazione:''' quando cambiando un elemento nella sequenza in una precisa posizione, le proprietà chimiche e fisiche restano invariate. | ||
| + | |||
| + | [[categoria:appunti]] | ||
Versione attuale delle 16:02, 2 ott 2008
Questa pagina è un copia-incolla poderoso degli appunti di El Conte, che li ha generosamente pubblicati su musicomio e che ringrazio infinitamente. L'impaginazione verrà sistemata al più presto e vedrò anche di integrare eventuali punti mancanti/carenti/non chiari, ammesso che ne trovi...
Promesso!
Indice
- 1 Sistemi informativi, basi di dati e DBMS
- 2 Progettazione di una base di dati
- 3 Il modello entità-associazione (ER)
- 4 Il modello relazionale
- 5 MIR SYSTEM
Sistemi informativi, basi di dati e DBMS
Il sistema informativo
Un sistema informativo è la componente (o il sottosistema) di una organizzazione che gestisce, acquisisce, elabora, conserva, produce, le informazioni di interesse, cioè utilizzate per il perseguimento degli scopi dell’organizzazione stessa.
Ogni organizzazione ha un sistema informativo, anche se può essere eventualmente non esplicitato nella struttura. Quasi sempre il sistema informativo è di supporto ad altri sottosistemi, e va quindi studiato nel contesto in cui è inserito. Inoltre è di solito suddiviso in sottosistemi (in modo gerarchico o decentrato), più o meno fortemente integrati tra loro.
Il sistema informatico è invece la parte del sistema informativo che gestisce informazioni per mezzo della tecnologia informatica.
La presenza di un sistema informatico all'interno di un sistema informativo non è obbligatoria: il concetto di “sistema informativo” è indipendente da qualsiasi automatizzazione. Esistono infatti organizzazioni la cui ragione d’essere è la gestione di informazioni (es: servizi anagrafici e banche) e che per secoli hanno operato senza l'ausilio dell'informatica.
Gestione delle informazioni
Nelle attività umane, le informazioni vengono gestite (registrate e scambiate) in forme diverse, a seconda delle necessità e capacità:
- idee informali
- linguaggio naturale (scritto o parlato, formale o colloquiale, in una lingua o in un’altra)
- disegni, grafici, schemi
- numeri
- codici (anche segreti)
E su vari supporti, dalla memoria umana alla carta.
Nelle attività standardizzate dei sistemi informativi complessi, sono state introdotte col tempo forme di organizzazione e codifica delle informazioni.
Ad esempio, nei servizi anagrafici si è iniziato con registrazioni discorsive e sono state poi introdotte informazioni via via più precise:
- nome e cognome
- estremi anagrafici
- codice fiscale
In particolare, nei sistemi informatici (e non solo in essi), le informazioni vengono rappresentate attraverso i dati.
Si dice informazione tutto ciò che produce variazioni nel patrimonio conoscitivo di un soggetto detto percettore dell'informazione.
Si dice dato una registrazione della descrizione di una qualsiasi caratteristica della realtà su un supporto che ne garantisca la conservazione e, mediante un insieme di simboli, ne garantisca la comprensibilità e la reperibilità.
Uno degli obiettivi fondamentali di un sistema di gestione dati è fornire un contesto interpretativo ai dati, in modo da consentire un accesso efficace alle informazioni da essi rappresentate.
Basi di dati e DBMS
In un'accezione generica, un database è una collezione di dati, utilizzati per rappresentare le informazioni di interesse per una o più applicazioni. In un'accezione più specifica, un database è una collezione di dati gestita da un DBMS.
Un DBMS (Database Management System) è un sistema (prodotto software) in grado di gestire collezioni di dati che siano:
- Grandi: di dimensioni (molto) maggiori della memoria centrale dei sistemi di calcolo utilizzati
- Persistenti: con un periodo di vita indipendente dalle singole esecuzioni dei programmi che le utilizzano
- Condivise: utilizzate da applicazioni diverse
Un DBMS deve garantire affidabilità (resistenza a malfunzionamenti hardware e software) e privatezza (mediante politiche di controllo degli accessi). Come ogni prodotto informatico, un DBMS deve essere efficiente, utilizzando al meglio le risorse di spazio e tempo del sistema, ed efficace, rendendo produttive le attività dei suoi utilizzatori.
La gestione di sistemi di dati grandi e persistenti è possibile anche tramite sistemi più semplici, quali gli ordinari file system dei sistemi operativi, che permettono di realizzare anche rudimentali forme di condivisione. I DBMS però estendono le funzionalità dei file system, fornendo più servizi ed in maniera integrata.
Caratteristiche dei DBMS
I maggiori vantaggi di un DBMS sono:
- l’indipendenza dei dati
- un loro accesso efficiente
- integrità e sicurezza
- amministrazione
- organizzazione degli accessi e ripristino da crash
- riduzione del tempo di sviluppo delle applicazioni.
Un DBMS è utile quando la quantità di dati è elevata e porterebbe ad un appesantimento operativo e/o quando si vogliono usare le sue potenzialità d’interrogazione dell’archivio di dati. Si dice transazione una qualunque esecuzione di un programma utenti in un DBMS.
Compito importante di un DBMS è la sequenzalizzazione di accessi concorrenti ai dati , così che ogni utente possa ignorare il fatto che altri stanno accedendo ai dati allo stesso tempo. Per fare ciò ci si serve di un meccanismo detto lock che serve a controllare l’acceso agli oggetti della base di dati. Un protocollo di locking è l'insieme di regole che ogni transazione deve seguire per garantire che l’effetto sia identico a quello ottenuto eseguendo tutte le transazioni in qualche ordine seriale.
Il DBMS mantiene un log di tutte le scritture sulla base di dati. Ogni azione di scrittura deve essere registrata prima di effettuare la modifica nella base di dati. Un WAL (write-ahead log) è usato nel caso il sistema andasse in crash appena fatto il cambiamento, ma prima che esso sia registrato nel log.
Un DBMS è dunque diviso in:
- Ottimizzatore d’interrogazioni che usa informazioni sulla memorizzazione dei dati per produrre un piano di esecuzione efficiente
- Piano di esecuzione, usato per valutare l’interrogazione
- Gestore dello spazio sul disco
- Gestore delle transazioni, assicura che le transazioni richiedano e rilascino i lock seguendo un buon protocollo di bloccaggio e programma l’esecuzione delle transazioni
- gestore dei lock, tiene traccia delle richieste dei lock
- gestore del ripristino, responsabile del mantenimento del log e del ripristino del sistema.
Un DBMS applica inoltre dei vincoli d’integrità, condizioni specificate dal DBA (Database Administrator) o dall’utente finale in uno schema di base dati, che limitano i dati memorizzabili in una istanza della base dati stessa. Ci sono vincoli statici (relativi ad uno stato della base di dati) e vincoli di transizione (relativi a stati diversi della base di dati).
Quando un’applicazione viene eseguita , il DBMS controlla se ci sono violazioni ai vincoli d'integrità e in quel caso non premette le modifiche ai dati.
Modelli di dati
Un modello di dati è un insieme di strumenti concettuali, o formalismo, che consta di tre componenti fondamentali:
- un insieme di strutture dati
- una notazione per specificare i dati tramite le strutture dati del modello
- un insieme di operazioni per manipolare i dati.
Generalmente si tratta di una struttura ad alto livello che nasconde molti dei dettagli di memorizzazione a basso livello. Un DBMS permette all’utente di definire i dati da memorizzare in termini di un modello di dati.
Un modello di dati semantico è un modello di dati ad alto livello che rende più semplice ad un utente creare una buona descrizione iniziale dei dati. Questi contengono una grande quantità di costrutti che aiutano a descrivere lo scenario di un’applicazione reale.
Al grado più elevato di astrazione troviamo i modelli concettuali, che permettono di rappresentare i dati in modo indipendente da ogni sistema, cercando di descrivere i concetti del mondo reale. Sono utilizzati nelle fasi preliminari di progettazione. Il più noto è il modello entità-relazione.
Scendendo di livello troviamo i modelli logici, utilizzati per l’organizzazione dei dati. Ad essi fanno riferimento i programmi, e sono indipendenti dalle strutture fisiche di memorizzazione. Ecco alcuni esempi di modelli logici: relazionale, reticolare, gerarchico, a oggetti...
E' importante che modelli simili favoriscano l'indipendenza dei dati. Tale proprietà si ottiene quando le applicazioni sono isolate dalle modifiche al modo in cui i dati sono strutturati e memorizzati.
Vi sono due tipi d’indipendenza dei dati:
- logica: i cambiamenti della struttura logica dei dati possono essere resi trasparenti agli utenti , cosi come la scelta delle relazioni da memorizzare
- fisica: lo schema logico isola gli utenti dai cambiamenti nei dettagli fisici di registrazione.
Progettazione di una base di dati
Analisi dei requisiti
Il primissimo passo nella progettazione è capire quali dati devono essere memorizzati, quali applicazioni devono essere costruite su di essi e quali operazioni sono più frequenti e soggette a requisiti prestazionali.
Per fare ciò vengono definite le caratteristiche della base di dati in maniera informale, mediante interviste con gli utenti, analisi di altre basi di dati esistenti, normative, ambiente operativo ecc.
L’output è un documento in linguaggio naturale di specifica dei requisiti, che si possono suddividere in alcune categorie principali:
- Requisiti informativi: caratteristiche e tipologie dei dati
- Requisiti sulle operazioni: esplicitati nel carico di lavoro
- Requisiti sui vincoli di integrità ed autorizzazione: proprietà da assicurare ai dati, in termini di correttezza e protezione
- Requisiti sulla popolosità della base di dati: volume dei dati
Progettazione concettuale
Le informazioni raccolte nel passo di analisi dei requisiti vengono usate per elaborare una descrizione ad alto livello dei dati da memorizzare.
Questo passo è sviluppato usando il modello entità-relazione, il quale fa parte di una famiglia di diversi modelli di dati ad alto livello, o semantici, usati nella progettazione delle basi di dati. Lo scopo è creare una semplice descrizione dei dati che approssimi il modo in cui utenti e sviluppatori pensano ad essi.
Progettazione logica
Bisogna poi scegliere un DBMS per implementare il progetto, e convertire la progettazione concettuale in uno schema nel modello del DBMS scelto. La traduzione non è sempre univoca.
Raffinamento dello schema
Si analizza l’insieme di relazioni dello schema relazionale per identificare potenziali problemi e per rifinirlo.
Progettazione fisica della base di dati
Si considerano i carichi di lavoro attesi che la nostra base di dati dovrà sopportare, e si raffina il progetto per garantire che esso soddisfi i criteri di prestazioni richieste.
Questo può consistere nella costruzione di indici su qualche tabella e nel raggruppamento di alcune tabelle, oppure può coinvolgere una riprogettazione sostanziale di intere parti dello schema ottenuto precedentemente.
Progettazione delle applicazioni e della sicurezza
Il modello entità-associazione (ER)
Cos'è
Il modello entità-relazione è il modello concettuale più usato nella progettazione concettuale di una base di dati di tipo relazionale. E' dotato di un proprio diagramma, noto come diagramma ER, che consente di rappresentare graficamente la struttura ad alto livello della base di dati. E' anche noto come modello entità-relazione (entity-relationship), ma useremo l'altra traduzione per non generare ambiguità con le caratteristiche del modello relazionale.
Il modello entità-associazione si basa su tre concetti fondamentali: quello di entità, di attributo e di associazione (o relazione).
Entità
Un'entità è un oggetto nel mondo reale (concreto o astratto) che si distingue da altri progetti. Vi sono anche insiemi di entità, e questi non hanno bisogno di essere disgiunti. Un entità è anche un'astrazione della realtà la cui informazione è indipendente dal dominio in cui l’entità è utilizzata. Invece un’istanza di entità sono specifici oggetti appartenenti ad una certa entità.
Attributi
Un’entità è descritta usando un insieme di attributi. Tutte le entità di un dato insieme hanno gli stessi attributi: questo è ciò che s’intende con simili. Viene chiamata attributo la coppia <nome_di_attributo, dominio> e ogni entità è caratterizzata da uno o più attributi.
Gli attributi possono essere monovalore (un solo valore memorizzato alla volta, es. l'età di una persona), multivalore (più valori possibili, es. gli esami sostenuti da uno studente) e compositi (es. un indirizzo, che è scomponibile iv via, n. civico, CAP e città).
Per ogni attributo associato ad un insieme di entità, dobbiamo definire un dominio di valori possibili. Vi son diversi tipi di domini:
- Semplice: sono domini standard(interi, reali, booleani…), con intervalli ed insiemi di valori definiti per enumerazione dall’utente,
- Composti: l’insieme dei valori è dato dal prodotto cartesiano degli insiemi di valori associati ai domini componenti. Servono per associare un dominio agli attributi composti.
Le informazioni sui domini di un attributo non sono direttamente rappresentabili in un diagramma ER, sono però fondamentali per una corretta progettazione logica.
Inoltre per ciascun insieme di entità useremo una chiave. Questa è un insieme minimale di attributi i cui valori identificano univocamente una entità dell’insieme. Potrebbe esserci più di una chiave candidata, e in questo caso ne designiamo una come chiave primaria. Una chiave non può avere valori nulli, in alcuni casi la chiave può essere soltanto una dove il sistema non permette di averne di più.
Gli attributi vengono rappresentati con degli ovali, e se sono sottolineati sono delle chiavi primarie mentre le entità sono dei rettangoli.
Associazioni
Un'associazione mette in relazione fra loro due o più entità. Come per le entità si può raccogliere un gruppo di associazioni simili in un insieme di associazioni.
Anche un'associazione può avere attributi che la descrivono, i quali son usati per registrare informazioni sulla relazione, piuttosto che su ciascuna delle entità partecipanti.
Un’istanza di un insieme di relazioni è un insieme di relazioni, questa può esser vista come una “fotografia” dell’insieme di relazioni di un certo istante. Gli insiemi di entità che partecipano ad una relazione non devono necessariamente essere distinti: qualche volta una relazione può coinvolgere entità dello stesso insieme.
Il ruolo è la funzione che un’istanza di entità esercita nell’ambito di un’associazione. Nel caso di un’associazione unaria il ruolo è sempre necessario (es. in un'associazione unaria che coinvolge due istanze dell'entità FILM, una avrà il ruolo di sequel e l'altra di "prequel").
Il modello relazionale
Cos'è
Il modello relazionale è il modello logico più noto ed è quello che viene solitamente implementato in un DBMS. E' stato proposto da E. F. Codd nel 1970 per favorire l’indipendenza dei dati e reso disponibile in DBMS reali nel 1981. Si basa sul concetto matematico di relazione, questo fornisce al modello una base teorica che permette di dimostrare formalmente proprietà di dati e operazioni.
Una relazione consiste in uno schema relazionale e nelle sue istanze di relazione. Lo schema specifica il nome della relazione, il nome di ogni campo (o attributo), ed il dominio di ciascun campo. Un'istanza di relazione è la "realizzazione concreta" dello schema relazionale e può essere vista come una tabella con righe, dette tuple o record, divise nei campi contenenti i dati. I campi di ciascuna tupla devono corrispondere per numero e tipo ai campi dello schema relazionale.
Il grado di una relazione è il numero dei campi presenti. La cardinalità di un'istanza di relazione è il numero di tuple in essa.
Una collezione d'istanze di relazione, una per ogni schema di relazione nello schema di una base di dati relazionale, forma un'istanza della base di dati.
Vincoli di integrità
Affinché uno schema relazionale sia valido è necessario che le tuple nelle sue istanze siano univocamente identificabili. In altre parole, non possono esistere in un'istanza tuple con valori identici in tutti i loro campi.
Il vincolo di chiave è l’imposizione che un certo sottoinsieme dei campi di una relazione sia un identificatore unico per una tupla. Tale insieme deve inoltre essere minimale, Ovvero non possono esistere sottoinsiemi propri dell'insieme selezionato che siano a loro volta identificatori unici di una tupla. Un insieme di campi di questo tipo si chiama chiave candidata per la relazione, o più semplicemente chiave.
Ogni relazione ha una chiave, e l’insieme di tutti i campi è una sottochiave. Possono esserci più chiavi candidate per una relazione, in tal caso se il DBMS non supporta chiavi multiple si indica come chiave primaria la chiave scelta per l'identificazione univoca delle tuple. Nella scelta di una chiave primaria è meglio usarne una che viene usata più frequentemente nelle interrogazioni.
Si può far riferimento ad una tupla in qualunque parte della base di dati memorizzando i valori dai campi della sua chiave primaria. In particolare, se una relazione R ha un insieme di attributi che costituisce la chiave di una relazione R', allora tale insieme è una chiave esterna di R su R'. Queste chiavi permettono di collegare tra loro tuple di relazioni diverse e costituiscono un meccanismo, per valore, per modellare le associazioni tra relazioni.
Una chiave esterna deve essere uguale alla chiave primaria della relazione referenziata, cioè deve avere lo stesso numero di colonne e tipi di dati compatibili, sebbene i nomi delle colonne possano essere diversi.
L'integrità referenziale rappresenta un importante vincolo d’integrità semantica. Difatti se una tupla t riferisce come valori di una chiave esterna i valori V1,...,Vn, allora deve esistere nella relazione riferita una tupla t' con valori di chiave V1,...,Vn. In altre parole, affinché vi sia un corretto riferimento tra due tuple, i valori della chiave primaria e della chiave esterna devono essere identici e coerenti tra loro.
Algebra relazionale
L'algebra relazionale è il linguaggio formale di interrogazione associato al modello relazionale. Le interrogazioni sono composte usando una collezione di operatori. Ognuno di questi deve accettare istanze di relazione come argomenti e restituisce un’istanza di relazione come risultato.
Un’espressione di algebra relazionale è ricorsivamente definita come una relazione, un operatore algebrico unario applicato ad una singola espressione o un operatore algebrico binario applicato a due espressioni.
Ogni interrogazione relazionale descrive una procedura passo-passo per calcolare la risposta desiderata, basandosi sull’ordine in cui gli operatori sono in essa applicati.
- Selezione
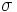 : l’operatore di selezione specifica le tuple da mantenere attraverso una condizione di selezione. Questa è una combinazione booleana di termini che hanno la forma attributo op costante oppure attributo1 op attributo2, dove op è uno degli operatori di confronto <,<=,=,=>,>,!=.
: l’operatore di selezione specifica le tuple da mantenere attraverso una condizione di selezione. Questa è una combinazione booleana di termini che hanno la forma attributo op costante oppure attributo1 op attributo2, dove op è uno degli operatori di confronto <,<=,=,=>,>,!=. - Proiezione
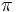 : l’operatore di proiezione invece ci permette di estrarre colonne da una relazione.
: l’operatore di proiezione invece ci permette di estrarre colonne da una relazione.
Le operazioni possibili sugli insiemi sono:
- Unione: R
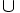 S restituisce un’istanza di relazione contenente tutte le tuple presenti nell’istanza di relazione R oppure S. Due istanze sono dette compatibili rispetto all’unione quando hanno lo stesso numero di campi e quando campi corrispondenti hanno lo stesso dominio.
S restituisce un’istanza di relazione contenente tutte le tuple presenti nell’istanza di relazione R oppure S. Due istanze sono dette compatibili rispetto all’unione quando hanno lo stesso numero di campi e quando campi corrispondenti hanno lo stesso dominio. - Intersezione: R
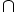 S restituisce un’istanza contenente tutte le tuple presenti sia in R che in S
S restituisce un’istanza contenente tutte le tuple presenti sia in R che in S - Differenza: R - S restituisce un’istanza contenente tutte le tuple presenti in R ma non in S. Le relazioni devono essere compatibili all’unione, e lo schema del risultato è identico a R
- Prodotto cartesiano: R x S restituisce un’istanza di relazione il cui schema contiene tutti i campi di R seguiti da tutti i campi di S. Il risultato di R x S contiene una tupla |r,s|.
- Rinomina
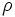 : usato per rinominare le tabelle.
: usato per rinominare le tabelle. - Join: usato per combinare informazioni da due o più relazioni. Un predicato di join esprime una relazione che deve essere verificata dalle tuple risultato dell’interrogazione. Vi sono diversi tipi di join:
- Join condizionale: la versione più generale dell’operatore di join accetta una condizione di join c e un paio di istanze di relazione come argomenti, restituendo un’istanza di relazione.
- Equijoin: lo si ha quando la condizione di join consiste solamente di uguaglianze della forma R.nome1 = S.nome2. In questo caso mantenere entrambi gli attributi sarebbe ridondante. Per le condizioni di join che contengono solo queste uguaglianze l’operazione di join è completata con una ulteriore proiezione in cui S.nome2 viene scartato. Lo schema del risultato di un equijoin contiene i campi di R, seguiti dai campi di S che non appaiono condizioni di join.
- Join naturale: è un equijoin in cui le uguaglianze sono specificate su tutti i campi aventi lo stesso nome in R e S. Questo tipo di join gode della proprietà per cui il risultato è certamente privo di coppie di campi con lo stesso nome.
- Join esterni (pg99): questi si basano sui valori null, aggiungono al risultato le tuple R e S che non hanno partecipato al join, completandole con NULL. La forma è R OUTER JOIN S. Esistono diverse varianti dell’OUTER JOIN:
- FULL: sia le tuple di R che quelle di S che non partecipano al join vengono completate ed inserite nel risultato,
- LEFT: le tuple di R che non partecipano al join vengono completate ed inserite nel risultato,
- RIGHT: le tuple S che non partecipano al join vengono completate ed inserite nel risultato.
- Cross join: Corrisponde al prodotto cartesiano. La sua forma è R CROSS JOIN S
- Divisione: l’operazione di divisione R / S è l’insieme di tutti valori di x (in forma di tuple unarie) tali che per ogni valore y in S ci sia una tupla |x,y| in R. L’idea di fondo è di calcolare tutti i valori di x che non sono interdetti. Un valore è interdetto se unendo a esso un valore y di B si ottiene una tupla |x,y| che non è in A. Le tuple interdette possono essere calcolate così:
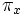 (((A) x B) – A).
(((A) x B) – A).
MIR SYSTEM
Lo scopo di questi sistemi è di permettere a qualsiasi utente di eseguire ricerche su tutta la musica esistente, attraverso interfacce con cui poter fornire al sistema descrizioni esaustive, nel modo più naturale possibile fornendo applicazioni utili a collegare e manipolare l’informazione ritornata dal sistema.
Descrizione dell'informazione musicale
L’informazione musicale può essere descritta attraverso sette aspetti (Downie):
Pitch Facet
Descrive la qualità del suono percepita che è principalmente una funzione della sua frequenza fondamentale.
Rappresentazione del pitch:
- note sul pentagramma
- nome (A, B, C...)
- pitch class number (0, 1, 2...)
- solfeggio (do, re, mi...)
Intervallo: è la differenza tra due pitch espressa in semitoni o attraverso la sua caratteristica tonale determinata dalla posizione dei due pitch nella sintassi tradizionale (quinta giusta, terza minore...).
Melodia: insieme di pitch o intervalli percepiti in modo sequenziale nel tempo.
Contorno melodico: il pattern degli intervalli.
Chiave: viene considerato come sub-aspetto del pitch. Due contorni melodici con pitch assoluto diverso ma con la medesima distribuzione di intervalli sono considerati percettivamente equivalenti (melodie trasposte).
Temporal Facet
Descrive l'informazione relativa alla durata degli eventi musicali che include:
- Metrica
- Indicatori di tempo
- Durata del pitch
- Accenti
- Durata armonica
Questi elementi costituiscono la parte ritmica del brano (questo può essere rappresentato in diversi modi, ognuno dei quali definisce uno stesso risultato).
Pause: possono essere considerate indicatori della durata degli eventi musicali che non contengono pitch.
L'informazione temporale può essere:
- Assoluta (metronomo ),
- Generale (adagio, forte ),
- Relativa (schneller, langsamer),
- Temporal distorsion (rubato, rallentando).
Harmonic Facet
Quando due o più pitch suonano simultaneamente, definita anche come polifonia. Interazione tra pitch e aspetto temporale per creare la polifonia (caratteristica fondamentale della musica occidentale).
Gli eventi armonici, sebbene presenti nella partitura, non sono sempre indicati esplicitamente. La mente umana può percepire un accordo, nonostante la presenza di note “extra”.
Timbral Facet
Comprende tutti gli aspetti del colore del tono. La distinzione tra una nota suonata da un flauto ed un clarinetto è causata dalla differenza del timbro. Fanno parte di questo aspetto le informazioni sulla composizione dell’orchestra, e anche l’enumerazione degli strumenti, ma non lo completano dal momento che tecniche esecutive diverse possono far generare al medesimo strumento timbri totalmente diversi (es. corda sfregata/martellata/pizzicata).
Editorial Facet
Istruzioni sull’esecuzione (diteggiatura, ornamenti, istruzioni dinamiche, etc). Tutta la partitura potrebbe essere inclusa in questo aspetto (le note stesse rappresentano istruzioni esecutive). Quasi sempre l'editorial facet non è codificato in maniera completa nella partitura, poiché viene completato dall'interpretazione personale dell'esecutore.
Textual Facet
E' l'aspetto più indipendente dalla melodia e dagli arrangiamenti associati. Un frammento di lirica in alcuni casi non è sufficiente per ritrovare il brano ricercato e viceversa, dal momento che potrebbero esserci più brani (o riarrangiamenti, o cover) che potrebbero far uso dello stesso testo.
Bibliographic Facet
A questo campo appartengono tutti i metadati, informazioni aggiuntive relative al brano ma non contenute intrinsecamente in esso. Sono informazioni relative a:
- titolo
- compositore
- arrangiatore
- editore
- numero di catalogo
- data pubblicazione
- esecutori
Progettazione di un MIR system
Uno degli obiettivi principali del MIR è permettere l’organizzazione dei dati per recuperare tutta l’informazione disponibile riguardante un certo brano musicale.
Per la costruzione di un DB musicale vi sono tre passi:
- Individuare lo scopo dei dati. In questa fase è necessario definire come le informazioni devono essere collezionate ed inserite nel DB, quali relazioni esistono tra loro e quali tipi di interrogazioni rendere disponibili all’utente finale.
- Elencare i dati necessari, considerando le sorgenti d’informazione disponibili. Le informazioni testuali sono solitamente più ricche e frequenti di quelle multimediali a causa delle problematiche legate al copyright.
- Definire la miglior struttura per questo corpo. In pratica come le informazioni vengono classificate ed organizzate, o qual è il miglior standard con cui scrivere queste informazioni. Senza una buona struttura l’uso e l’accesso del DB diventa inutile e complicato, la sua efficienza ne risente come la sua manutenzione.
Una volta definito il DB è necessario definire le interfacce e le tipologie d’interrogazione da fornire all’utente. Vi sono tre tipi di ricerca:
- Browsing: può essere un mezzo utile per cercare in un sistema ricco di collegamenti tra i dati ed i metadati, e permette di passare da un brano all’altro attraverso diversi collegamenti.
- Textual search: indicizzazione di tutte le informazioni testuali accademiche (autore, titolo...) e non accademiche (genere, frammenti delle liriche...).
- Search by content: confronto tra i complessi contenuti musicali presenti nella base di dati e contenuti musicali meno complessi introdotti come criterio di ricerca. queste interrogazioni sono generalmente basate sulla melodia o altri aspetti del contenuto audio. servono a trovare un brano di cui non si conoscono informazioni quali il titolo, l’autore, o altri metadata sufficienti per individuarlo. Usato anche per il copyright in modo da capire se un brano è molto simile ad un altro.
Naturalmente si possono combinare le varie tipologie di ricerca per aumentare la potenza e l’efficienza del sistema.
La maniera di mostrare i risultati cambia l’utilità e le manipolazioni possibili dei dati restituiti dal sistema. I dati restituiti devono essere sufficienti a riconoscere quale brano nella lista dei risultati è quello ricercato, e una volta riconosciuto l’utente deve poter accedere a tutte le informazioni collegate, suddivise per tipologia (informazioni di catalogo e testuali, link ai meta-dati, link ad altri oggetti musicali).
Un altro aiuto nella ricerca sono le informazioni di catalogo che limitano la ricerca alla sola musica conosciuta. Uno dei più grandi e potenti descrittori usati dai consumatori di musica è il genere musicale, difatti due brani appartenenti allo stesso genere musicale hanno molti più elementi in comune rispetto a due brani non appartenenti allo stesso genere.
Generalmente gli strumenti musicali aiutano a definire il genere.
Catalog information: sono le informazioni che descrivono i brani musicali, non strettamente correlate al contenuto musicale. Descrivono chi ha preso parte alla realizzazione del brano, dove è stato registrato, informazioni sul supporto e sul copyright.
Multimedia characteristics: sono metadadati che descrivono qualcosa di strettamente legato al contenuto musicale, e le informazioni associate col ricordo del frammento usato nella query-by-content.
Valutazione della qualità
Per valutare un sistema MIR si deve controllare che sia molto efficiente ed affidabile.
Per affidabilità intendiamo che il sistema deve permetter di trovare tutte e sole le informazioni richieste dall’utente. Queste devono essere sempre corrette (da verificare quando i dati sono elaborati automaticamente).
La complessità dei sistemi MIR è dovuta soprattutto all’enorme quantità di oggetti musicali.
Query by content
Il criterio su cui si basa la query-by-content è il frammento musicale. Per realizzare questo approccio vengono solitamente usati due tipi di DB:
- a frammenti tematici: contengono frammenti che rappresentano i tempi musicali presenti nei brani. Il tema in questo caso viene considerato come una sequenza di note ripetuta diverse volte all’interno della composizione musicale. Una sequenza di note invece è considerata un tema se nella composizione esistono altre sequenze ottenute da questo attraverso qualche operatore musicale.
- database di intere partiture: sono presenti tutte le melodie contenute in tutte le voci dell’intera partitura, perché un utente potrebbe ricordare un solo frammento del brano non appartenente al tema.
Sequenze di note: ogni elemento della sequenza è descritto da qualche parametro (solitamente nome e durata della nota).
Query-by-humming: il frammento musicale viene introdotto canticchiando o fischiettando la melodia da cercare. può risultare non accurata ed è per utenti non esperti.
Gli approcci per questo metodo sono di due tipi:
- DSP: elaborazione della forma d’onda o delle frequenze per trovare similarità tra i brani. Vi è una trasformazione in simbolico, dove vengono estrapolate le caratteristiche descriventi gli eventi musicali. Questo sistema risulta molo faticoso e complesso.
- Simbolico: trasformazione dei brani in sequenze di stringhe di caratteri rappresentanti le sequenze melodiche contenute nei brani. Il frammento della query viene trasformato allo stesso modo e quindi confrontato con le stringhe nel DB.
Come criterio per le query-by-content viene usato l’audio (si definisce attraverso l’analisi delle frequenze esistenti nello spettro del segnale in ogni istante di tempo discreto il corrispondente pitch). In input avremo un frammento audio (non strutturato per definizione) ed in output le caratteristiche capaci di definire i note-pattern.
Vi sono dei problemi legati alla trascrizione da audio a simbolico:
- Note segmentation: dove sono posizionate esattamente le note? Quanto durano?
- Pitch variation della nota suonata: come individuare l’esatta altezza della nota suonata?
- Note quantization: come posizionare le altezze sulle scale musicali?
Purtroppo viene difficile capire quale nota deve essere associata all’altezza del suono, infatti non esiste sempre una corrispondenza esatta.
Lo stesso discorso vale per la rappresentazione simbolica, infatti esistono molte tipologie del formato. Possiamo avere casi dove la stessa altezza viene rappresentata in più modi diversi o il nome della nota può rappresentare più altezze (di differenti ottave).
A volte per ovviare a questi problemi, tutte le rappresentazioni della stessa nota vengono collassate in una sola. L’alfabeto di 12 elementi viene usato per rappresentare e dividere le altezze in semitoni, questo però comporta una perdita d’informazione sul contorno melodico. Si applicano poi degli algoritmi di trasposizione per calcolare la similarità, 12 volte su ogni sequenza. Viene usato questo metodo nei sistemi dove l’elaborazione è limitata agli incipit.
Tecniche di conversione simbolica
Sequenza d’intervalli: distanza tra due note adiacenti misurata in semitoni. La sequenza melodica è data dalla sequenza delle distanze tra un elemento e il suo successore. Come risultato si ha un perdita della nozione di nota come elemento d’ottava. È dimostrato che l’uomo ascoltando un brano non ha l’esatta percezione dell’altezza delle note, ma ricorda più facilmente la sequenza degli intervalli.
Contorno melodico: si considera solo la direzione tra una nota ed il suo successore. È possibile rappresentare la sequenza melodica con solo 3 simboli: up, down, equal to. Questo però permette di avere una trascrizione di query-by-humming corretta, e se la melodia è abbastanza lunga è possibile individuare univocamente il brano cercato.
Rappresentazione Frame-based: Non si ha la segmentation, in pratica non si divide ogni singolo evento della melodia. Il tempo viene diviso in frame di ugual misura, e viene stimato il valore di un pitch per ogni frame. Le note non sono esplicitamente descritte, in un unico valore sono rappresentabili le informazioni relative ad altezza e durata. Lo svantaggio di questo metodo è che si perde l’informazione relativa al ritmo.
La lunghezza media di un query fragment è pari a 7 note. Ciò significa ottenere centinaia di brani simili, impossibili da ascoltare tutti per trovare quello corretto. Questo sistema è però utile come operazione di “pre-processing”, per scremare il contenuto del DB prima di usare un metodo più sofisticato.
Criteri di similarità
Classi di equivalenza: ogni simbolo rappresenta n intervalli.
- C1: ogni simbolo rappresenta un intervallo,
- C3: ogni simbolo rappresenta 3 diversi intervalli adiacenti,
- CU: tutti gli intervalli crescenti e decrescenti collassato in due differenti classi (contorno melodico ).
Music psychology: c’è un alta probabilità che qualche errore sia presente nel frammento dell’interrogazione, difatti anche utenti esperti possono non essere in grado di rappresentare in modo esatto la melodia del brano che stanno cercando. Inoltre, non è sempre detto che il frammento della query rappresenti in modo esatto la melodia del brano che si sta cercando, in punti adiacenti del brano, l’utente potrebbe ricordarsi la melodia di differenti parti, costruendo una nuova melodia.el caso di brani polifonici poi, bisogna definire come una sequenza di note sia riconosciuta dall’uomo come una melodia in mezzo alle altre voci.
Il concetto di similarità varia in funzione di:
- memoria, che può essere a breve o lungo termine,
- tipologia di utente, che va dal non esperto,al mediamente esperto e all’esperto.
String matching and melodic similarity: approccio tra i più utilizzati per risolvere il problema della similarità melodica. Una semplice formalizzazione del problema contestualizzato nell’ambito dello string matching potrebbe essere: sia f la stringa di caratteri che rappresenta il frammento melodico criterio di un’interrogazione e s la stringa di caratteri che rappresenta la partitura di un brano presente nel DB:
- f è fattore di x?
- se f non appare in x, quale sottoparte di f è presente in s?
- quante volte un’approssimazione di f è presente in s?
Blast algorithm: Basic Local Alignment Search Tool, uno tra i metodi più efficaci utilizzati per l’elaborazione di database biologici. Permette d’individuare in due sequenze zone uguali o simili e allineamenti globali.
Il grado di similarità tra le due sequenze mostra la correlazione. Questa può essere basata su:
- Identità percentuale: numero di elementi uguali nello stesso ordine presenti nelle due sequenze rispetto al numero totale di elementi.
- Conservazione: quando cambiando un elemento nella sequenza in una precisa posizione, le proprietà chimiche e fisiche restano invariate.